深浅模式
DCNv4
一、本文介绍(💯)
本文给大家带来的改进机制是2024-1月的最新成果DCNv4,其是DCNv3的升级版本,效果可以说是在目前的卷积中名列前茅了,同时该卷积具有轻量化的效果!一个DCNv4参数量下降越15Wparameters左右。它主要通过两个方面对前一版本DCNv3进行改进:首先,它移除了空间聚合中的softmax归一化,这样做增强了其动态特性和表达能力;其次,它优化了内存访问过程,以减少冗余操作,从而加快处理速度。DCNv4的表现可以说是非常的全面,同时该网络为新发目前存在大量使用Bug我均已修复。

二、DCNv4原理

论文地址:论文官方地址
代码地址:代码官方地址

2.1 DCNv4的基本原理
DCNv4(Deformable Convolution v4)是一种改进的卷积网络操作符,专为提高计算机视觉应用的效率和效果而设计。它主要通过两个方面对前一版本DCNv3进行改进:首先,它移除了空间聚合中的softmax归一化,这样做增强了其动态特性和表达能力;其次,它优化了内存访问过程,以减少冗余操作,从而加快处理速度。这些改进使DCNv4在各种视觉任务中,例如图像分类和生成,表现出更快的收敛速度和更高的处理效率。
DCNv4的主要特点可以分为以下两点:
1. 动态特性增强:通过移除空间聚合中的softmax归一化,DCNv4增强了其动态特性和表达能力。
2. 内存访问优化:DCNv4优化了内存访问过程,减少了冗余操作,从而提高了处理速度。
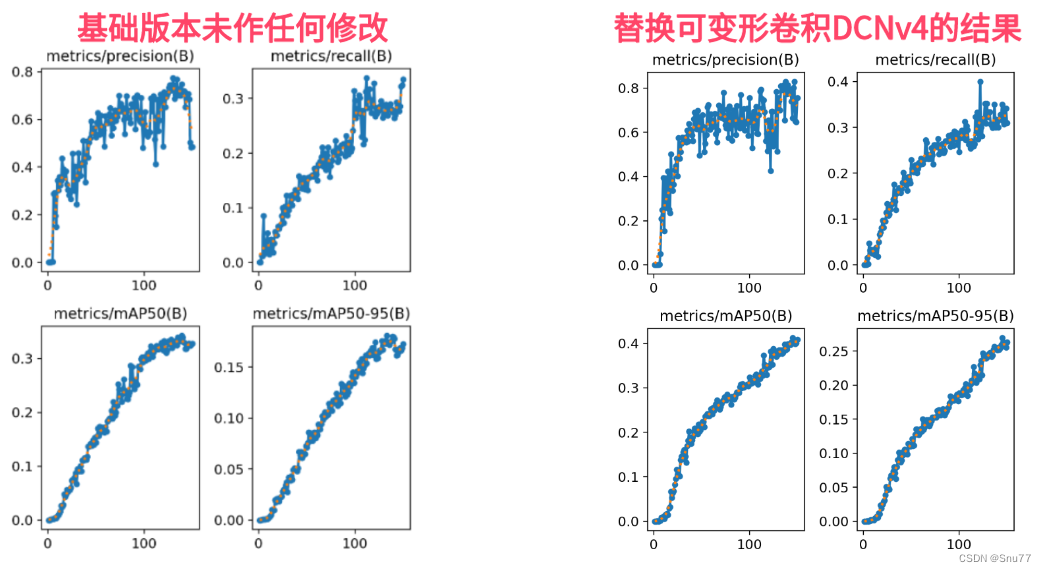
下图展示了DCNv4与其他空间聚合核心操作符的比较:
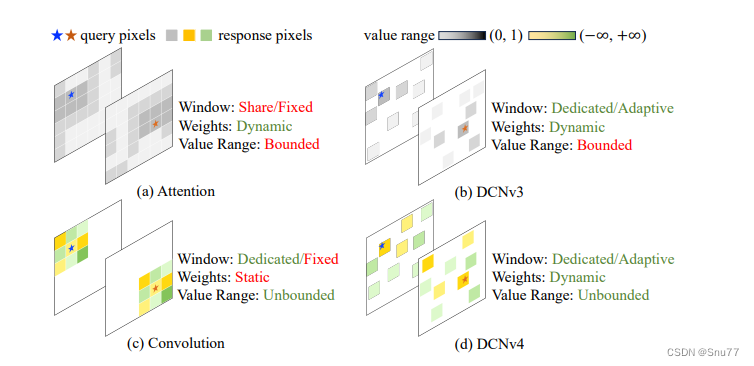
在处理同一通道内不同位置的查询像素时:
a) DCNv3使用有界(0到1范围内)动态权重聚合空间特征,采样点集(注意力集)对于每个位置是相同的。
b) DCNv3对于每个位置使用一个专用的窗口。
c) 传统卷积提供更灵活的无界值范围以聚合权重,并使用固定形状和大小的窗口。
d) DCNv4结合了动态形状和大小的窗口、自适应感受野以及无界值范围的动态聚合权重,对于每个位置都是输入依赖的。
2.2 动态特性增强
在DCNv4中,动态特性增强的实现对于计算机视觉模型的适应性和灵活性是一个重要进步。这一特性使得DCNv4能够更加有效地处理图像中的形变和动态变化,尤其是在那些需要精细调整感受野以识别不同尺寸和形状对象的场景中。通过去除之前版本中的softmax归一化,DCNv4的每个卷积核都能自适应地调整其聚合权重,对每个像素的响应不再受到固定范围的限制。这种灵活性的增加对于提升模型在处理不同分辨率、不同尺度的物体时的性能至关重要,尤其是在图像生成和高级图像理解任务中表现得更为明显。
2.3 内存访问优化
下图展示了DCNv4在优化内存访问方面的改进:
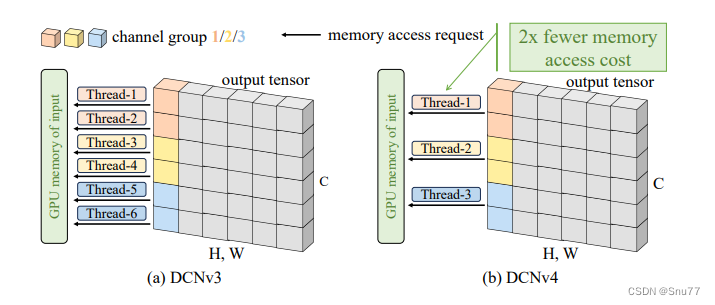
与DCNv3相比,DCNv4使用一个线程来处理同一组中的多个通道,这些通道共享采样偏移和聚合权重。这种方法减少了像内存读取和双线性插值系数计算这样的工作量,并且可以合并多个内存访问指令。结果是,DCNv4减少了内存访问需求,如图所示,与DCNv3相比,它能够减少一半的内存访问输出张量。这种优化提高了处理速度,并减少了计算资源的使用。
三、DCNv4的核心代码
3.1 DCNv4的核心代码
该网络目前涉及到编译处理操作,代码结构无法进行重构组成,只能提供文件的形式给大家,小伙伴也可以通过如下的百度云链接进行下载。
百度网盘链接:https://pan.baidu.com/s/13qjv9TzVGsC4ranCkHMCHg
提取码:Snu7
3.2 C2f_DCNv4代码
python
import torch.nn as nn
import torch
from ultralytics.nn.DCNv4_op.DCNv4.modules.dcnv4 import DCNv4
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = DCNv4(c2)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_DCNv4(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
x = self.cv1(x)
x = x.chunk(2, 1)
y = list(x)
# y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))四、手把手教你使用DCNv4
首先需要注意的是,目前该卷积尚未提供Pytorch版本,发布的版本需要编译才可以运行,Windows系统很难编译可能20个里面能编译成功一个就不错了,所以建议大家使用该结构的时候利用Linux系统来使用,进行租用服务器,不会租用服务器训练的读者,可以入群看群内视频,我已发布如何利用服务器训练的教程视频。
4.1 修改一
我们将下载好的文件复制粘贴到如下的目录文件下'ultralytics/nn'。粘贴后的文件目录构造如下图所示->
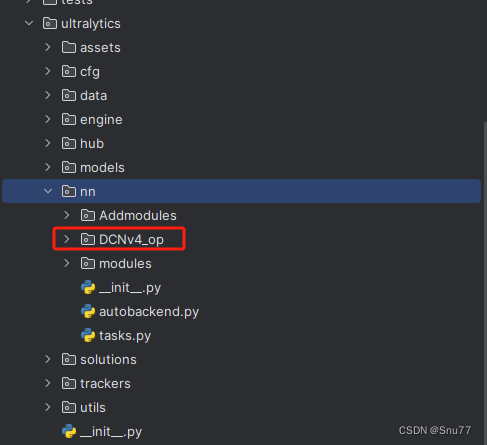
4.2 修改二
第二步我门中到我们复制进去文件里的如下文件进行编译'ultralytics/nn/DCNv4_op/make.sh',
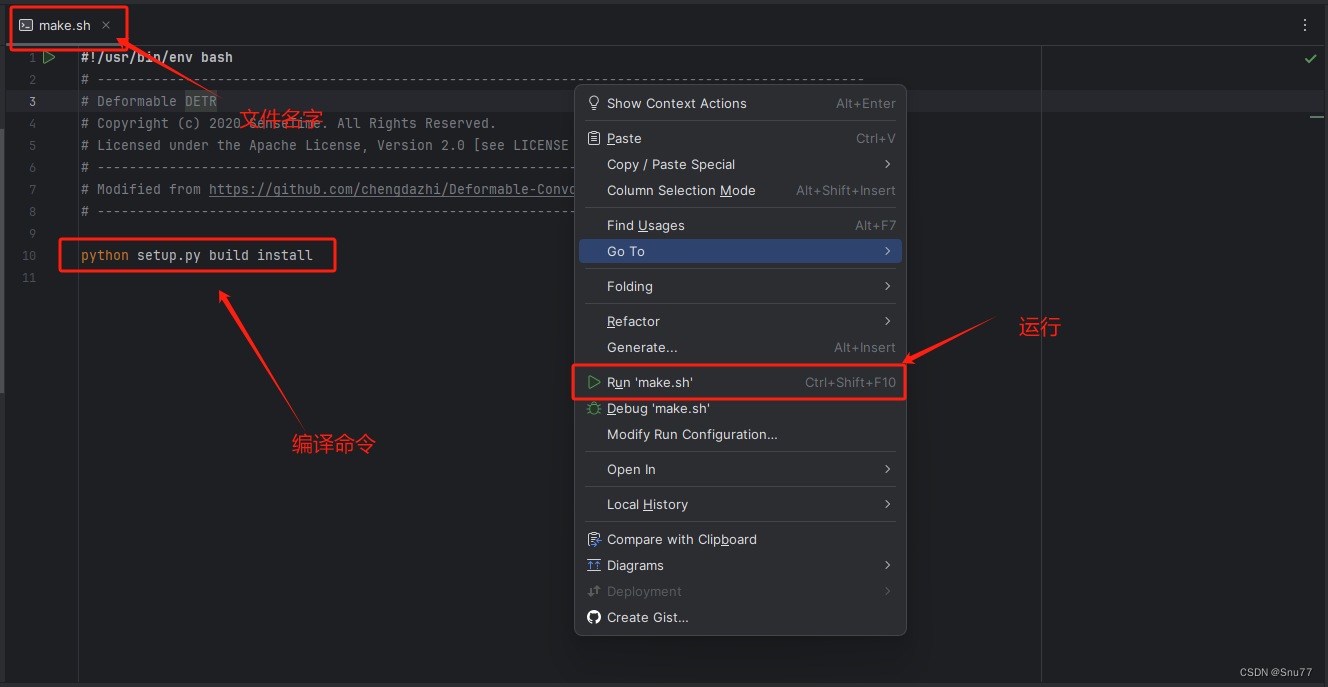
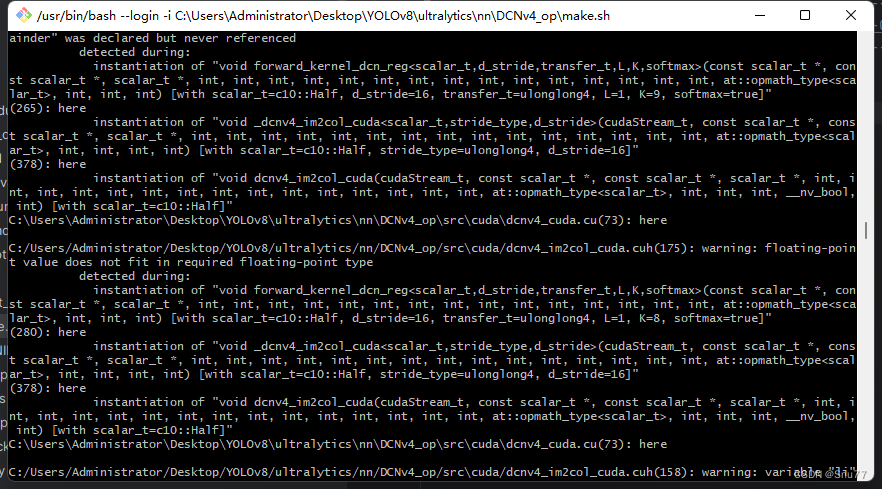
之后弹出窗口进行编译,如果成功最后会有成功的提示的。
4.3 修改三
第三步我们编译成功之后,我们就可以使用了,需要注意的是该模块无法替换主干上的普通的卷积,只能搭配C2f来使用。
我们将章节3.2 中的提到的C2f_DCNv4的代码进行如下的步骤添加即可。
我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹,然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
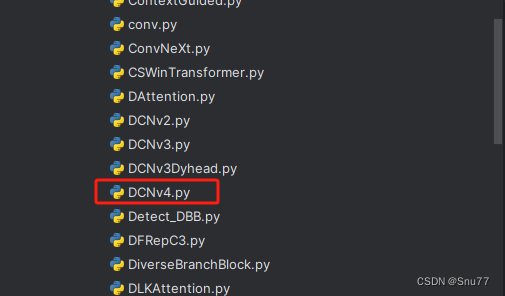
4.4 修改四
第二步我们在该目录下创建一个新的py文件名字为'__init__.py',然后在其内部导入我们的检测头如下图所示。
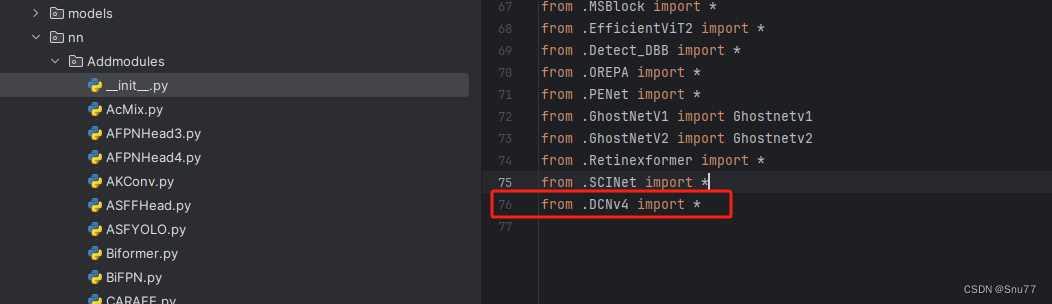
4.5 修改五
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块。
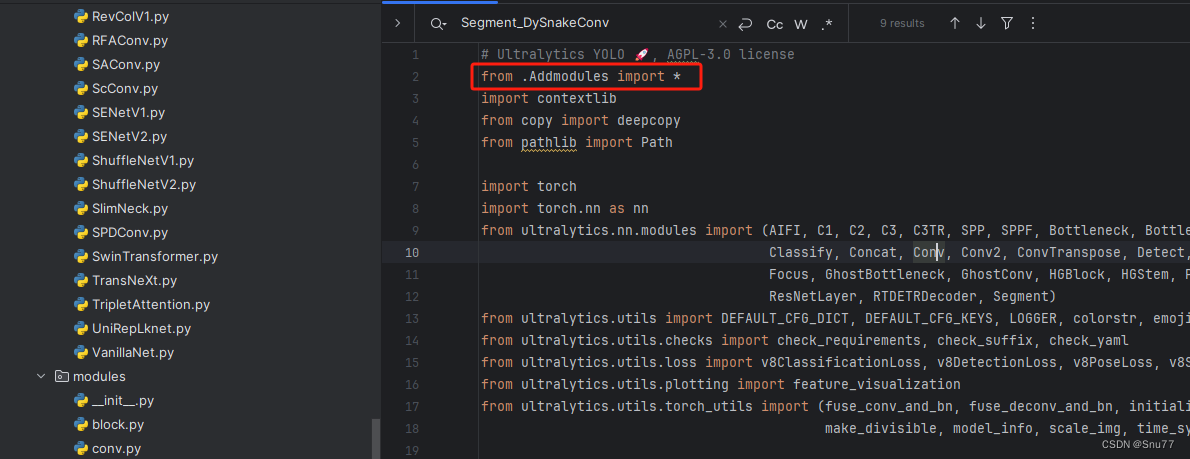
4.6 修改六
按照我的添加在parse_model里添加即可。
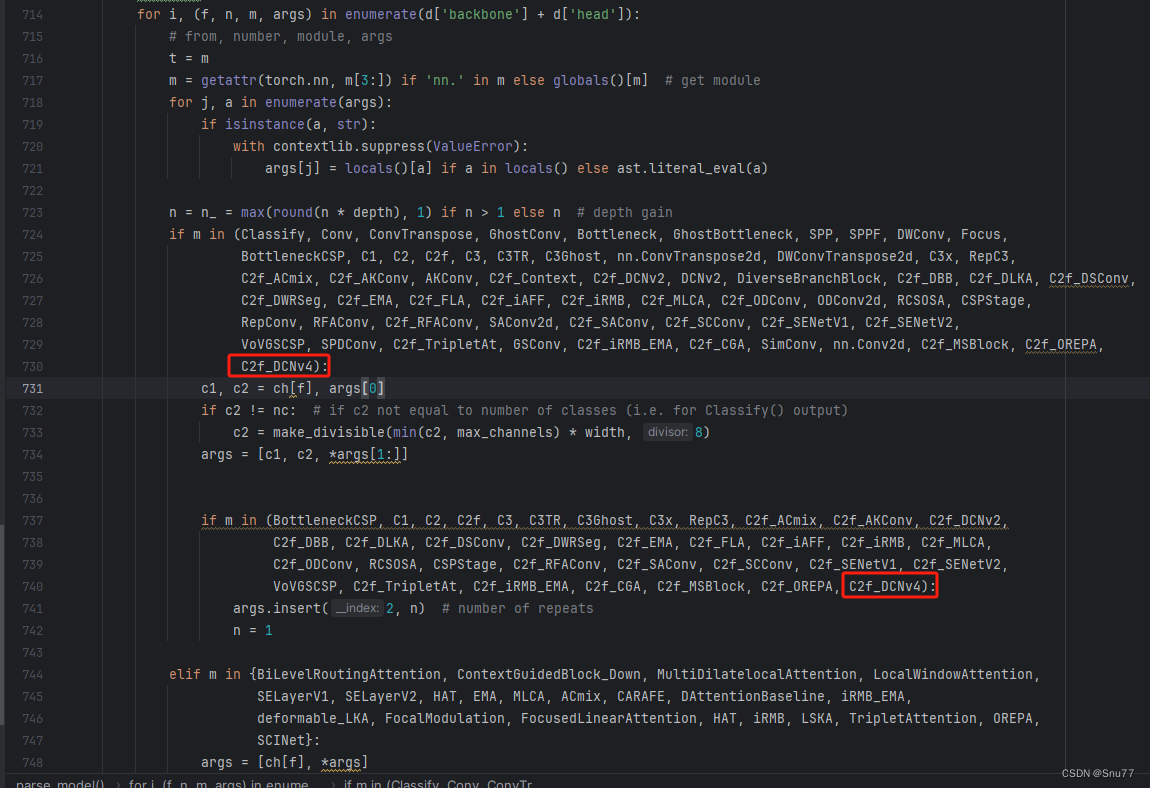
4.7 修改七
此步需要仔细修改大家不修改此步会报模型不能够定义在CPU上的错误,还是这个文件'ultralytics/nn/tasks.py''然后我们按照图片进行修改。
python
try:
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward on CPU
except RuntimeError:
try:
self.model.to(torch.device('cuda'))
m.stride = torch.tensor([s / x.shape[-2] for x in forward(
torch.zeros(1, ch, s, s).to(torch.device('cuda')))]) # forward on CUDA
except RuntimeError as error:
raise error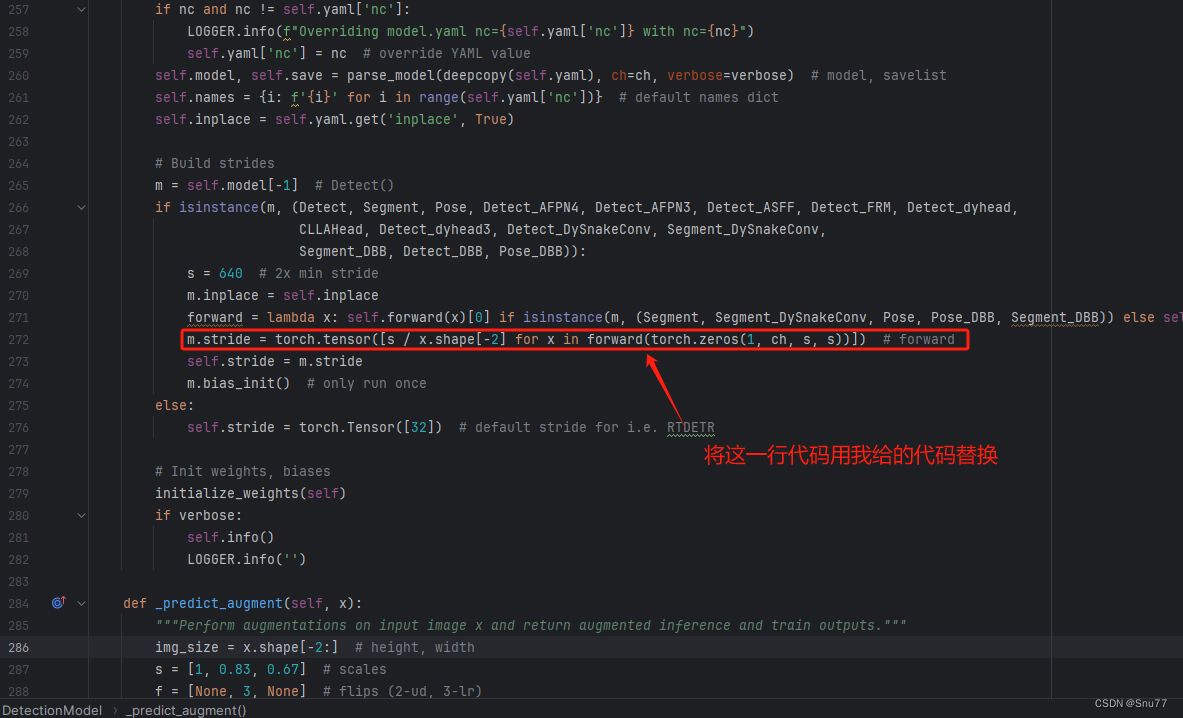
替换完成的样子如下图所示
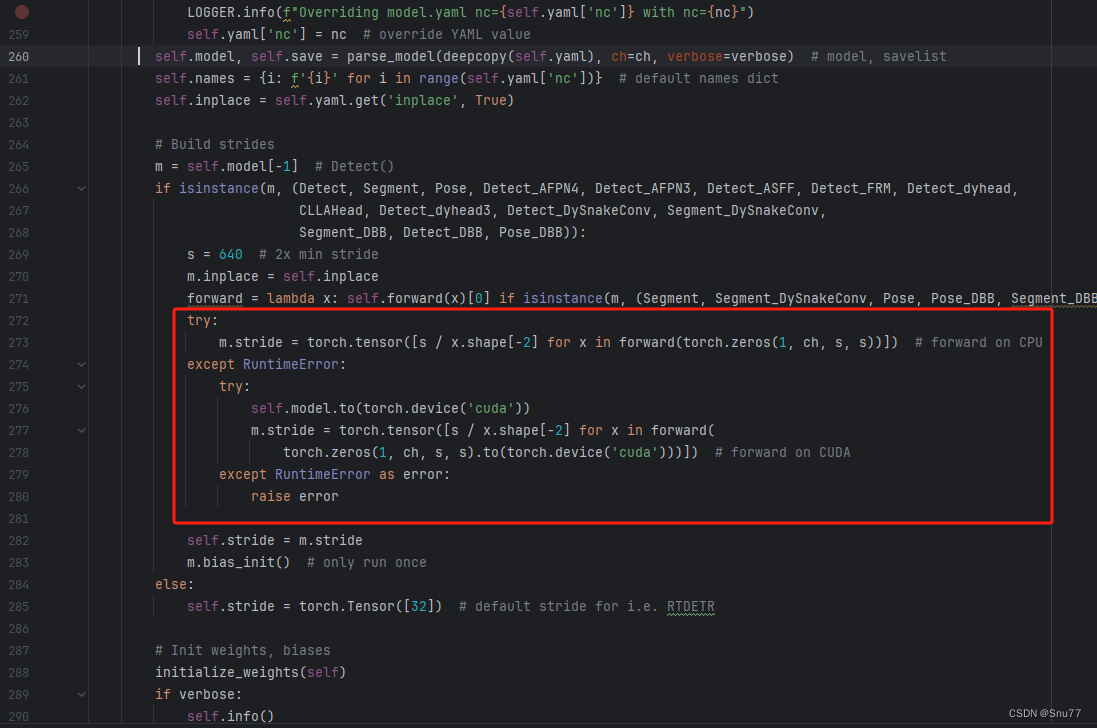
到此就修改完成了,大家可以复制下面的yaml文件运行。
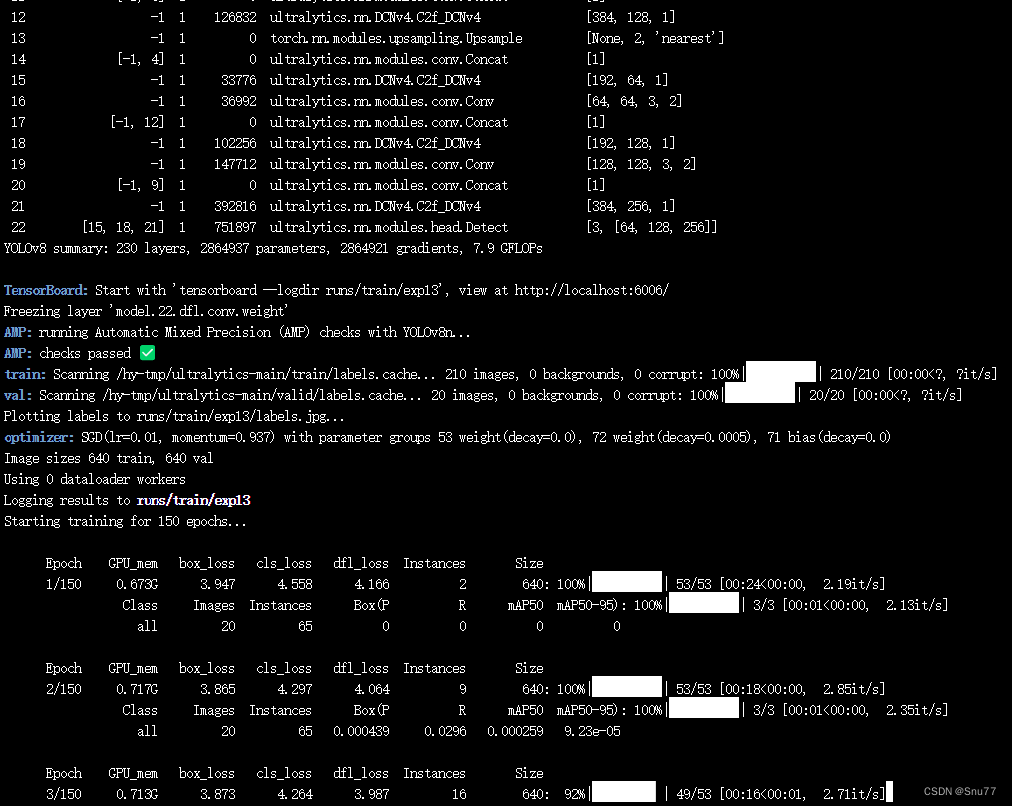
五、C2f_DCNv4的yaml文件和运行记录
5.1 C2f_DCNv4的yaml文件一
下面的添加C2f_DCNv4是我实验结果的版本。
C2f该还不能够替换第一个C2f也会报错,其中的原因我还没来得及去看。
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_DCNv4, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_DCNv4, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_DCNv4, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5.2 C2f_DCNv4的yaml文件二
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f_DCNv4, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f_DCNv4, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f_DCNv4, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f_DCNv4, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5.3 C2f_DCNv4的训练过程截图