深浅模式
GELAN模块(💯)
一、本文介绍
本文给大家带来的改进机制是利用2024/02/21号最新发布的YOLOv9其中提出的GELAN模块来改进YOLOv8中的C2f,GELAN融合了CSPNet和ELAN机制同时其中利用到了RepConv在获取更多有效特征的同时在推理时专用单分支结构从而不影响推理速度,同时本文的内容提供了两种版本一种是参数量更低涨点效果略微弱一些的版本(参数量V8n下降80w,计算量为6.1GFLOPs),另一种是参数量稍多一些但是效果要不参数量低的效果要好一些(均为我个人整理),提供两种版本是为了适配不同需求的读者,具体选择那种大家可以根据自身的需求来选择即可,文章中我都均已提供,同时本文的结构存在大量的二次创新机会,后面我也会提供。
二、GELAN的原理
2.1 Generalized ELAN
在本节中,我们描述了提出的新网络架构 - GELAN。通过结合两种神经网络架构CSPNet和ELAN,这两种架构都是以梯度路径规划设计的,我们设计了考虑了轻量级、推理速度和准确性的广义高效层聚合网络(GELAN)。其整体架构如图4所示。我们推广了ELAN的能力,ELAN原本只使用卷积层的堆叠,到一个新的架构,可以使用任何计算块。
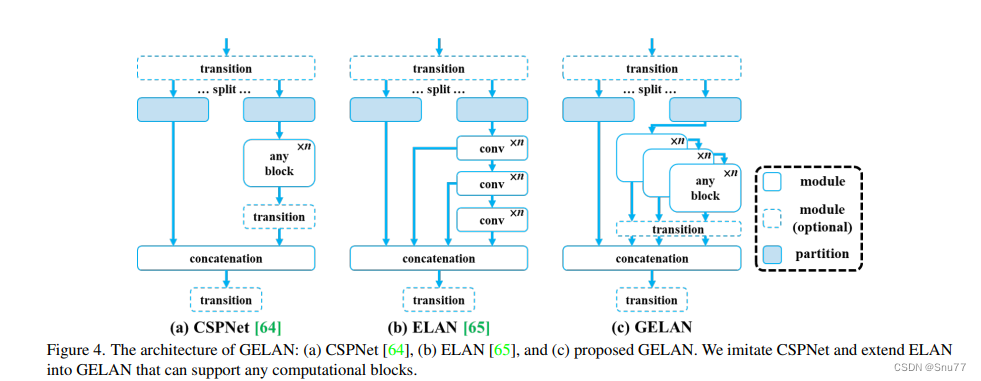
这张图(图4)展示了广义高效层聚合网络(GELAN)的架构,以及它是如何从CSPNet和ELAN这两种神经网络架构演变而来的。这两种架构都设计有梯度路径规划。
a) CSPNet:在CSPNet的架构中,输入通过一个转换层被分割为两部分,然后分别通过任意的计算块。之后,这些分支被重新合并(通过concatenation),并再次通过转换层。
b) ELAN:与CSPNet相比,ELAN采用了堆叠的卷积层,其中每一层的输出都会与下一层的输入相结合,再经过卷积处理。
c) GELAN:结合了CSPNet和ELAN的设计,提出了GELAN。它采用了CSPNet的分割和重组的概念,并在每一部分引入了ELAN的层级卷积处理方式。不同之处在于GELAN不仅使用卷积层,还可以使用任何计算块,使得网络更加灵活,能够根据不同的应用需求定制。
GELAN的设计考虑到了轻量化、推理速度和精确度,以此来提高模型的整体性能。图中显示的模块和分区的可选性进一步增加了网络的适应性和可定制性。GELAN的这种结构允许它支持多种类型的计算块,这使得它可以更好地适应各种不同的计算需求和硬件约束。
总的来说,GELAN的架构是为了提供一个更加通用和高效的网络,可以适应从轻量级到复杂的深度学习任务,同时保持或增强计算效率和性能。通过这种方式,GELAN旨在解决现有架构的限制,提供一个可扩展的解决方案,以适应未来深度学习的发展。
大家看图片一眼就能看出来它融合了什么,就是将CSPHet的anyBlock模块堆叠的方式和ELAN融合到了一起。
2.2 Generalized ELAN结构图
YOLOv9最主要的创新目前能够得到的就是其中的GELAN结构,我也是分析其代码根据论文将其结构图绘画出来。
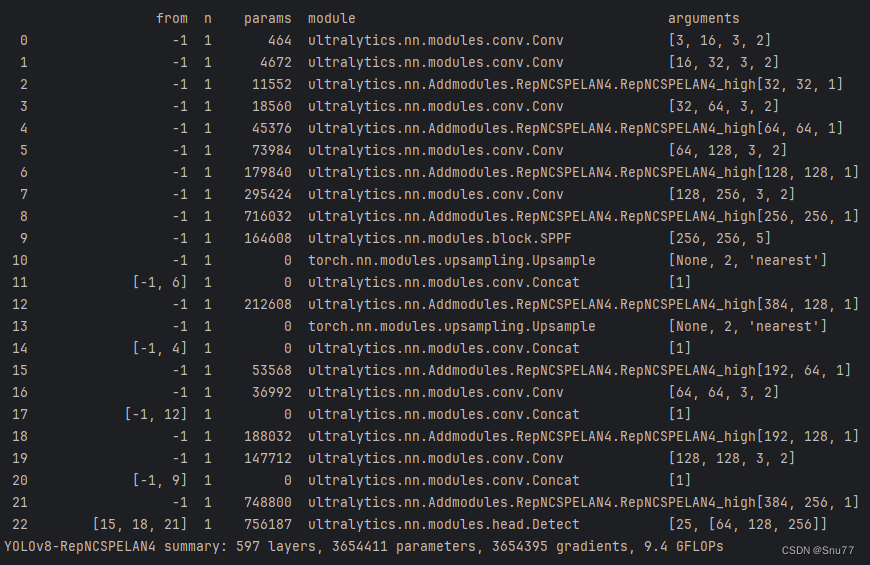
下面的文件为YOLOv9的yaml文件。可以看到的是其提出了一种结构名字RepNCSPELAN4,其中的结构图concat后的通道数我没有画是因为它有计算中间的参数的变量是根据个人设置来的。
其代码和结构图如下所示!
python
class RepNCSPELAN4(nn.Module):
# csp-elan
def __init__(self, c1, c2, c5=1): # c5 = repeat
super().__init__()
c3 = int(c2 / 2)
c4 = int(c3 / 2)
self.c = c3 // 2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepNCSP(c3 // 2, c4, c5), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
self.cv4 = Conv(c3 + (2 * c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))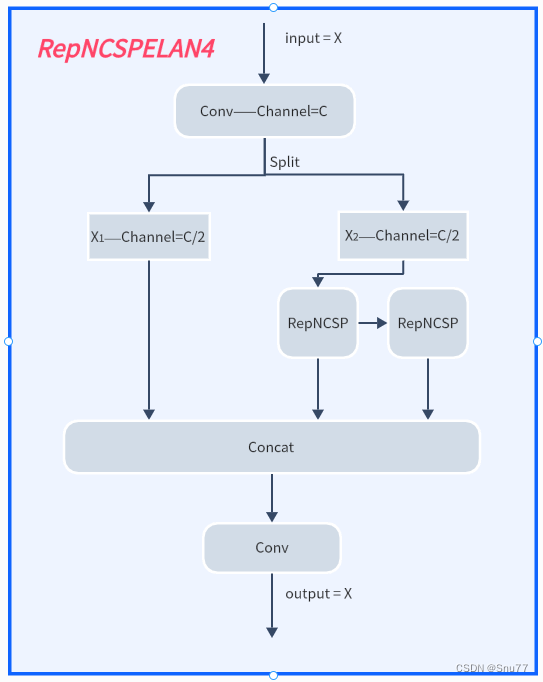
三、核心代码
核心代码的使用方式看章节四!
python
import torch
import torch.nn as nn
import numpy as np
__all__ = ['RepNCSPELAN4_low', 'RepNCSPELAN4_high']
class RepConvN(nn.Module):
"""RepConv is a basic rep-style block, including training and deploy status
This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
def forward_fuse(self, x):
"""Forward process"""
return self.act(self.conv(x))
def forward(self, x):
"""Forward process"""
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(x) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _avg_to_3x3_tensor(self, avgp):
channels = self.c1
groups = self.g
kernel_size = avgp.kernel_size
input_dim = channels // groups
k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
return k
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, 'id_tensor'):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def fuse_convs(self):
if hasattr(self, 'conv'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('conv1')
self.__delattr__('conv2')
if hasattr(self, 'nm'):
self.__delattr__('nm')
if hasattr(self, 'bn'):
self.__delattr__('bn')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
class RepNBottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = RepConvN(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class RepNCSP(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(RepNBottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class RepNCSPELAN4_low(nn.Module):
# csp-elan
def __init__(self, c1, c2, c5=1): # c5 = repeat
super().__init__()
c3 = int(c2 / 2)
c4 = int(c3 / 2)
self.c = c3 // 2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv3 = nn.Sequential(RepNCSP(c3, c3, c5))
self.cv4 = Conv(c3 + (2 * c4), c2, 1, 1)
def forward(self, x):
temp = self.cv1(x)
temp3 = self.cv3(temp)
y = list(temp.chunk(2, 1))
y.append(temp3)
temp2 = torch.cat(y, 1)
return self.cv4(temp2)
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
class RepNCSPELAN4_high(nn.Module):
# csp-elan
def __init__(self, c1, c2, c5=1): # c5 = repeat
super().__init__()
c3 = c2
c4 = int(c3 / 2)
self.c = c3 // 2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepNCSP(c3 // 2, c4, c5), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
self.cv4 = Conv(c3 + (2 * c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
if __name__ == "__main__":
# Generating Sample image
image_size = (1, 24, 224, 224)
image = torch.rand(*image_size)
# Model
mobilenet_v1 = RepNCSPELAN4_low(24, 24)
out = mobilenet_v1(image)
print(out.size())四、手把手教你添加GELAN机制
4.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹,然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
4.2 修改二
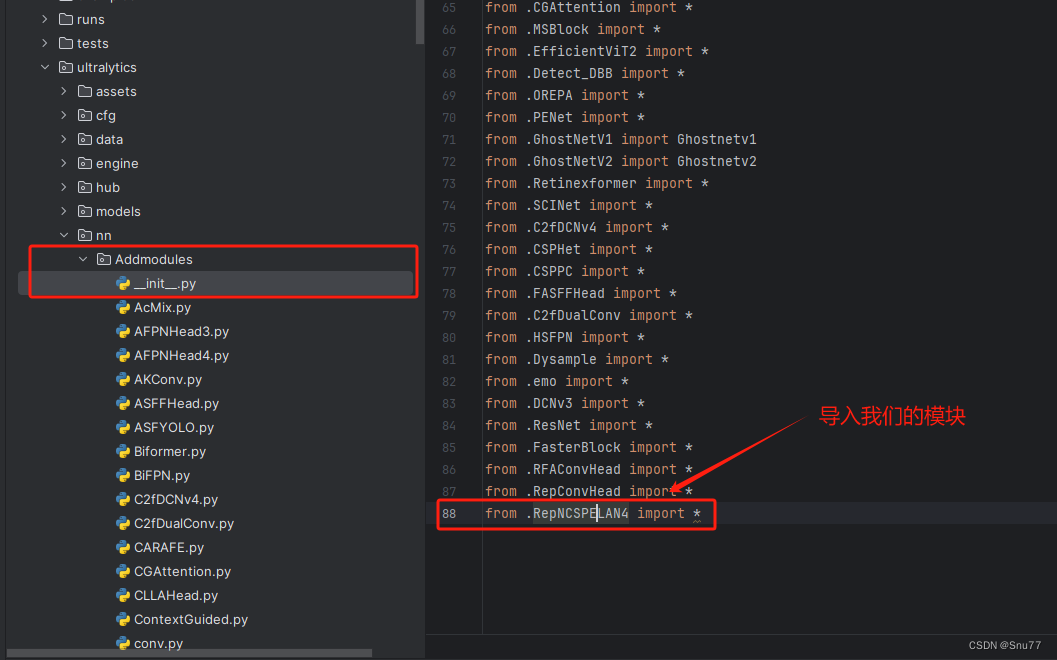
第二步我们在该目录下创建一个新的py文件名字为'__init__.py',然后在其内部导入我们的检测头如下图所示。
4.3 修改三
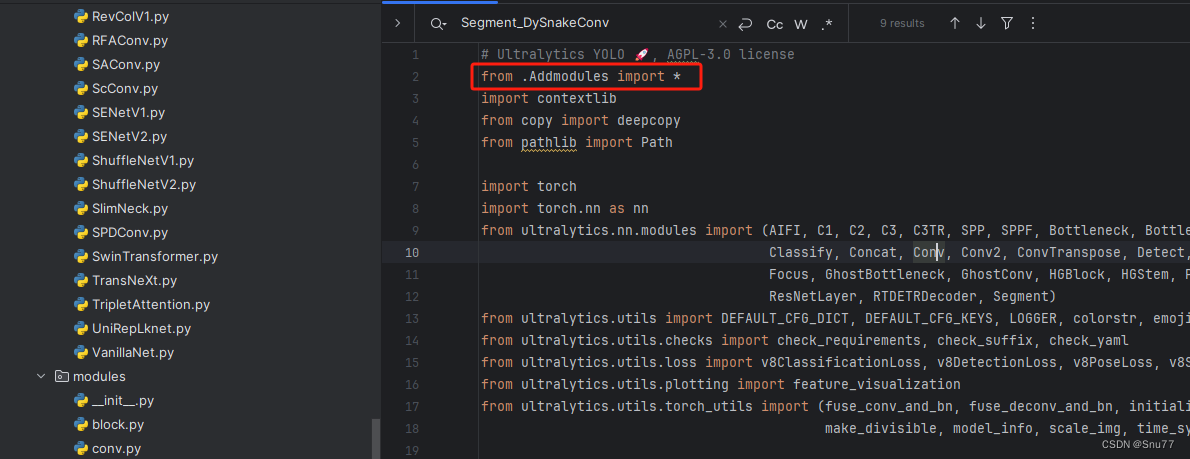
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块。
4.4 修改四
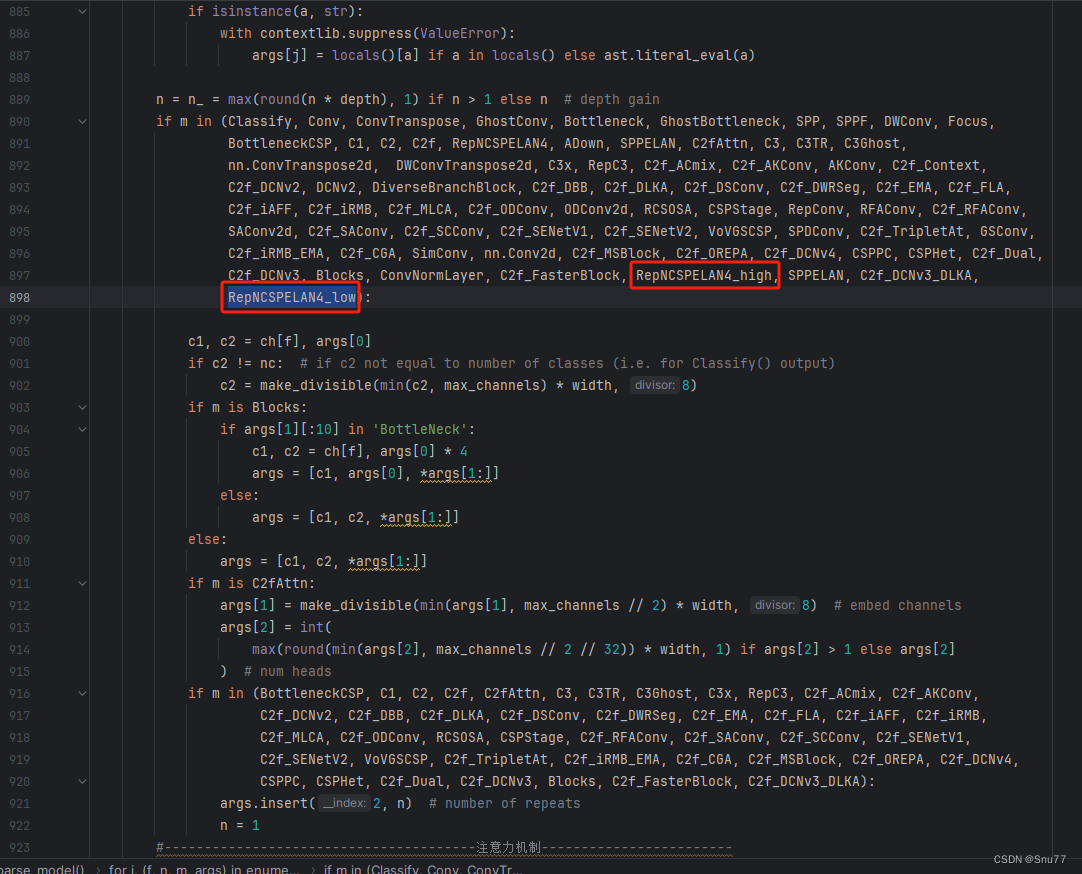
按照我的添加在parse_model里添加即可。
到此就修改完成了,大家可以复制下面的yaml文件运行。
五、GELAN的yaml文件和运行记录
5.1 GELAN低参数量版本的yaml文件
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 1, RepNCSPELAN4_low, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 1, RepNCSPELAN4_low, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 1, RepNCSPELAN4_low, [512]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 1, RepNCSPELAN4_low, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 1, RepNCSPELAN4_low, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 1, RepNCSPELAN4_low, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 1, RepNCSPELAN4_low, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 1, RepNCSPELAN4_low, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5.2 GELAN高参数量版本的yaml文件
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 1, RepNCSPELAN4_high, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 1, RepNCSPELAN4_high, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 1, RepNCSPELAN4_high, [512]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 1, RepNCSPELAN4_high, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 1, RepNCSPELAN4_high, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 1, RepNCSPELAN4_high, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 1, RepNCSPELAN4_high, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 1, RepNCSPELAN4_high, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5.3 训练代码
大家可以创建一个py文件将我给的代码复制粘贴进去,配置好自己的文件路径即可运行。
python
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8-C2f-FasterBlock.yaml')
# model.load('yolov8n.pt') # loading pretrain weights
model.train(data=r'替换数据集yaml文件地址',
# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, pose
cache=False,
imgsz=640,
epochs=150,
single_cls=False, # 是否是单类别检测
batch=4,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD', # using SGD
# resume='', # 如过想续训就设置last.pt的地址
amp=False, # 如果出现训练损失为Nan可以关闭amp
project='runs/train',
name='exp',
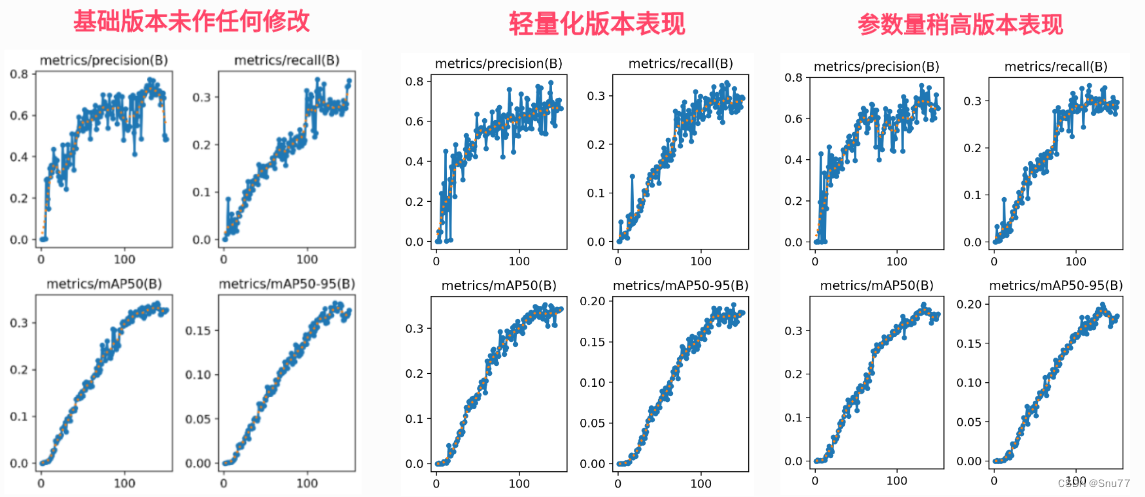
)5.3 GELAN的训练过程截图
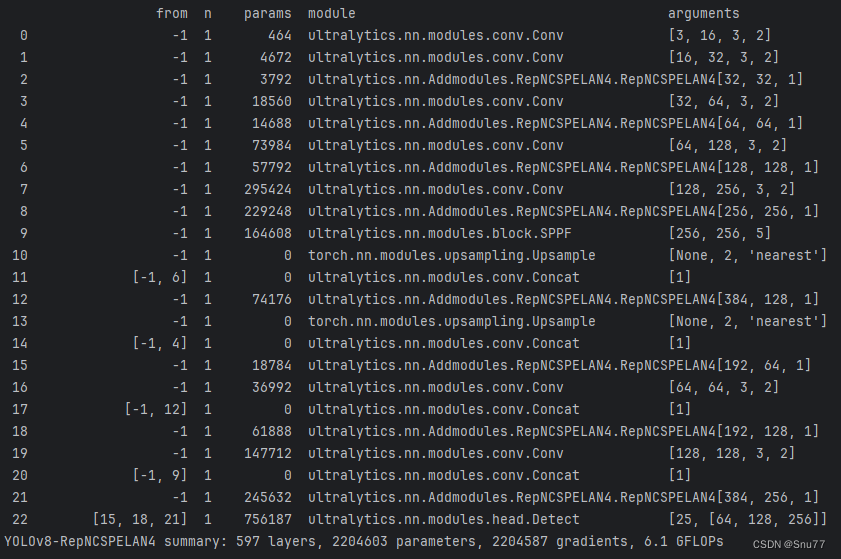
5.3.1 低参数量版本
5.3.2 高参数量版本