深浅模式
HWD替换传统下采样
一、本文介绍
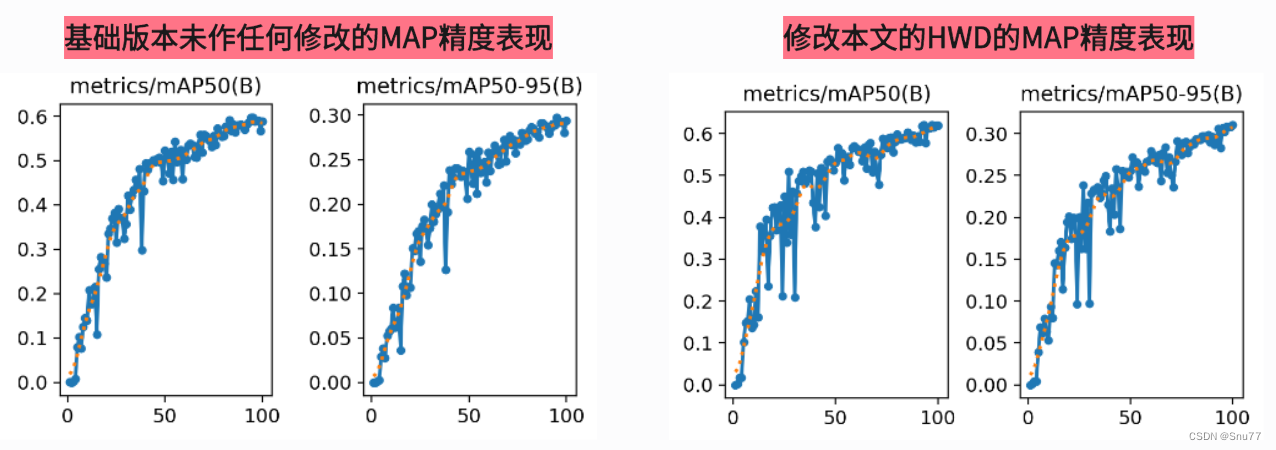
本文给大家带来的改进机制是Haar 小波的下采样HWD替换传统下采样(改变YOLO传统的Conv下采样)在小波变换中,Haar小波作为一种基本的小波函数,用于将图像数据分解为多个层次的近似和细节信息,这是一种多分辨率的分析方法。我将其用在YOLOv8上其明显降低参数和GFLOPs在V8n上使用该机制后参数量为270W,计算量GFLOPs为7.5。
二、原理介绍
官方论文地址:官方论文地址点击此处即可跳转(论文需要花钱此论文)
官方代码地址:官方代码地址点击此处即可跳转
论文介绍了一种基于Haar小波变换的图像压缩方法及其压缩图像质量的评估方法。下面是对论文内容的详细分析:
主要内容和方法
1. Haar小波变换的介绍:
- Haar小波是最简单的小波形式之一,具有易于计算和实现的优点。
- 文章中应用了二维离散小波变换(2D DWT),将图像信息矩阵分解为细节矩阵和信息矩阵。
- 重构图像使用这些矩阵和小波变换的信息完成。
2. 图像压缩技术:
- 压缩技术通过使用Haar小波作为基函数,减少图像文件大小,同时尽可能保持图像质量。
- 压缩过程包括将图像信息转换为更易于编码的格式,这通常涉及转换、量化和熵编码。
结论:论文证明了Haar小波变换是一种有效的图像压缩工具,尤其适合需要高压缩比而又不希望图像质量下降太多的应用场景。此外,通过对比传统的DCT和最新的小波变换方法,作者指出Haar小波在处理图像边缘和细节方面具有一定的优势,尤其是在压缩高分辨率图像时。
三、核心代码
python
import torch
import torch.nn as nn
try:
from pytorch_wavelets import DWTForward # 按照这个第三方库需要安装pip install pytorch_wavelets==1.3.0
# 如果提示缺少pywt库则安装 pip install PyWavelets
except:
pass
class Down_wt(nn.Module):
def __init__(self, in_ch, out_ch):
super(Down_wt, self).__init__()
self.wt = DWTForward(J=1, mode='zero', wave='haar')
self.conv_bn_relu = nn.Sequential(
nn.Conv2d(in_ch*4, out_ch, kernel_size=1, stride=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
)
def forward(self, x):
yL, yH = self.wt(x)
y_HL = yH[0][:,:,0,::]
y_LH = yH[0][:,:,1,::]
y_HH = yH[0][:,:,2,::]
x = torch.cat([yL, y_HL, y_LH, y_HH], dim=1)
x = self.conv_bn_relu(x)
return x
if __name__ == "__main__":
# Generating Sample image
image_size = (1, 64, 224, 224)
image = torch.rand(*image_size)
# Model
model = Down_wt(64, 32)
out = model(image)
print(out.size())四、手把手教你添加HWD机制
4.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn文件夹下建立一个目录名字呢就是'Addmodules'文件夹,然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py',然后在其内部导入我们的检测头如下图所示。
4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块。
4.4 修改四
按照我的添加在parse_model里添加即可。

到此就修改完成了,大家可以复制下面的yaml文件运行。
五、HWD的yaml文件和运行记录
PS:注意本文的改进机制需要关闭AMP运行否则会报精度错误!
PS:注意本文的改进机制需要关闭AMP运行否则会报精度错误!
5.1 HWD的yaml文件1
主干和Neck全部用上该卷积轻量化到机制的yaml文件。
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Down_wt, [128]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Down_wt, [256]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Down_wt, [512]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Down_wt, [1024]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Down_wt, [256]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Down_wt, [512]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5.2 HWD的yaml文件2
创新C2f的yaml文件2,PS:注意本文的改进机制需要关闭AMP运行否则会报精度错误!
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Down_wt, [128]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Down_wt, [256]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Down_wt, [512]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Down_wt, [1024]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5.3 训练代码
大家可以创建一个py文件将我给的代码复制粘贴进去,配置好自己的文件路径即可运行。
PS:注意本文的改进机制需要关闭AMP运行否则会报精度错误!
python
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8-C2f-FasterBlock.yaml')
# model.load('yolov8n.pt') # loading pretrain weights
model.train(data=r'替换数据集yaml文件地址',
# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, pose
cache=False,
imgsz=640,
epochs=150,
single_cls=False, # 是否是单类别检测
batch=4,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD', # using SGD
# resume='', # 如过想续训就设置last.pt的地址
amp=False, # 如果出现训练损失为Nan可以关闭amp
project='runs/train',
name='exp',
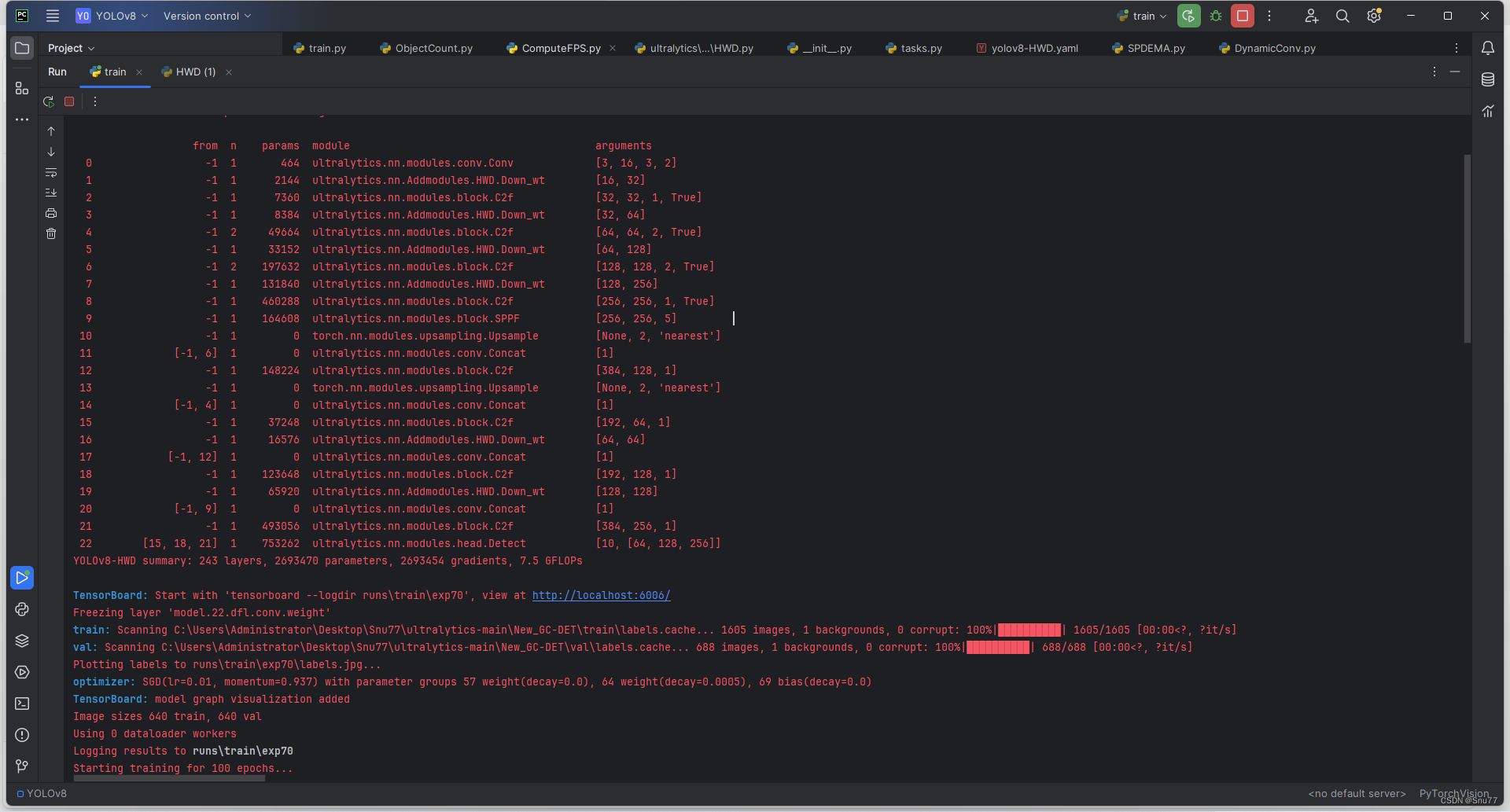
)5.4 HWD的训练过程截图
PS:注意本文的改进机制需要关闭AMP运行否则会报精度错误!