
深浅模式
计算FPS
一、本文介绍
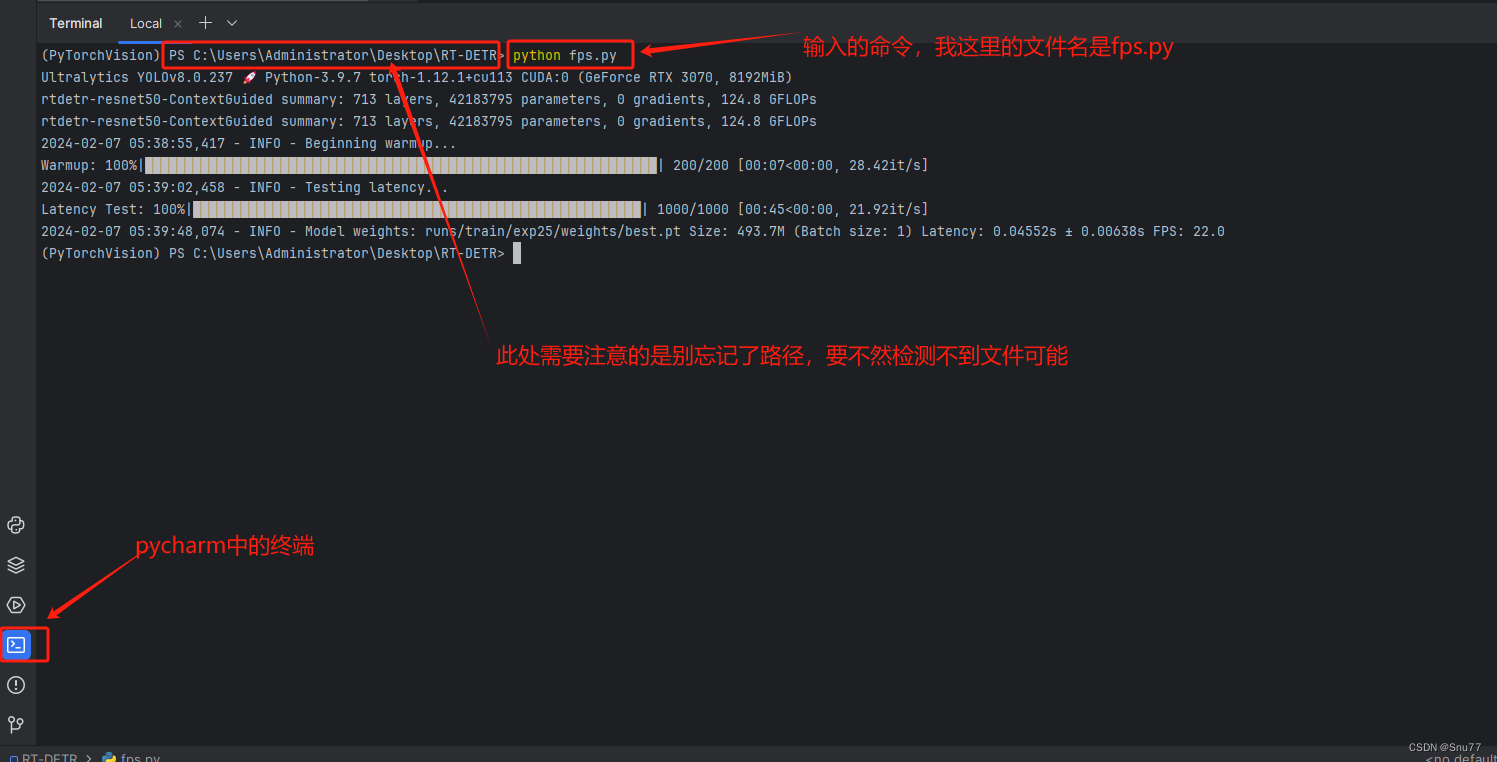
本文给大家带来的改进机制是利用我们训练好的权重文件计算FPS,同时打印每张图片所利用的平均时间,模型大小(以MB为单位),同时支持batch_size功能的选择,对于轻量化模型的读者来说,本文的内容对你一定有帮助,可以清晰帮你展示出模型速度性能的提升以及轻量化的效果(模型大小),对于以提高精度为目的的读者本文也能够帮助大家展示出现阶段的模型速度指标。所以本文的内容是十分有用的机制,对于大家发表论文来说,下面的图片为运行后的效果可以看到,该有的指标均已打印(本文内容为我独家创新,全网无第二份)。
欢迎大家订阅我的专栏一起学习YOLO!
二、核心代码
下面的为核心代码,我们将其复制粘贴到我们的ultralytics仓库的最外层目录下即可,创建一个py文件存放进去。
python
import warnings
warnings.filterwarnings('ignore')
import argparse
import os
import time
import numpy as np
import torch
import torch.utils.data
from tqdm import tqdm
from ultralytics.utils.torch_utils import select_device
from ultralytics.nn.tasks import attempt_load_weights
import logging
# 设置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def get_weight_size(path):
"""获取模型权重文件的大小(以MB为单位)。"""
try:
stats = os.stat(path)
return f'{stats.st_size / (1024 ** 2):.1f}'
except OSError as e:
logging.error(f"Error getting weight size: {e}")
return "N/A"
def warmup_model(model, device, example_inputs, iterations=200):
"""模型预热,准备进行高效推理。"""
logging.info("Beginning warmup...")
for _ in tqdm(range(iterations), desc='Warmup'):
model(example_inputs)
def test_model_latency(model, device, example_inputs, iterations=1000):
"""测试模型的推理延迟。"""
logging.info("Testing latency...")
time_arr = []
for _ in tqdm(range(iterations), desc='Latency Test'):
if device.type == 'cuda':
torch.cuda.synchronize(device)
start_time = time.time()
model(example_inputs)
if device.type == 'cuda':
torch.cuda.synchronize(device)
end_time = time.time()
time_arr.append(end_time - start_time)
return np.mean(time_arr), np.std(time_arr)
def main(opt):
device = select_device(opt.device)
weights = opt.weights
assert weights.endswith('.pt'), "Model weights must be a .pt file."
model = attempt_load_weights(weights, device=device, fuse=True)
model = model.to(device).fuse()
example_inputs = torch.randn((opt.batch, 3, *opt.imgs)).to(device)
if opt.half:
model = model.half()
example_inputs = example_inputs.half()
warmup_model(model, device, example_inputs, opt.warmup)
mean_latency, std_latency = test_model_latency(model, device, example_inputs, opt.testtime)
logging.info(f"Model weights: {opt.weights} Size: {get_weight_size(opt.weights)}M "
f"(Batch size: {opt.batch}) Latency: {mean_latency:.5f}s ± {std_latency:.5f}s "
f"FPS: {1 / mean_latency:.1f}")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Test YOLOv8 model performance.")
parser.add_argument('--weights', type=str, default='yolov8n.pt', help='trained weights path')
parser.add_argument('--batch', type=int, default=1, help='total batch size for all GPUs')
parser.add_argument('--imgs', nargs='+', type=int, default=[640, 640], help='image sizes [height, width]')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--warmup', default=200, type=int, help='warmup iterations')
parser.add_argument('--testtime', default=1000, type=int, help='test iterations for latency')
parser.add_argument('--half', action='store_true', help='use FP16 mode for inference')
opt = parser.parse_args()
main(opt)三、参数讲解
本文涉及到的参数共有如下。
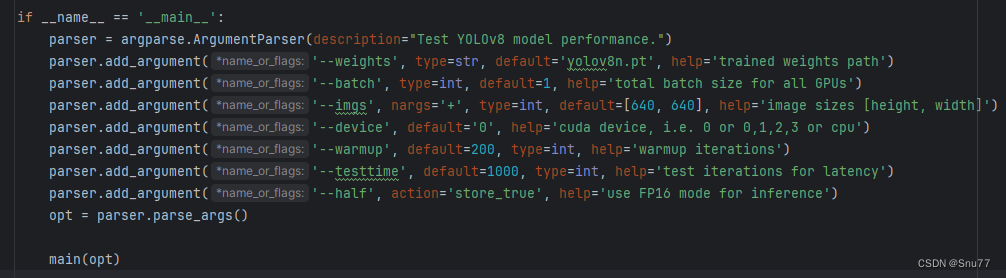
参数讲解如下
| 1 | weights | 对应的权重文件地址 |
| 2 | batch | 计算多少个图片的FPS |
| 3 | imgs | 图片的大小默认为640 |
| 4 | device | 推理的设备选择,默认为GPU:0 |
| 5 | warmup | 预测轮次,预热阶段目的是让模型运行在一个更稳定的状态,提高模型推理性能 |
| 6 | testtime | 参数定义了进行性能评估时执行的推理轮次数,这个参数使得性能测试更加准确和可靠。通过在足够多的轮次上测量推理时间,可以减少偶然因素的影响,并获得一个更加稳定和准确的性能指标 |
| 7 | half | 推理精度这个不多介绍了大家都懂,FPS16更快 |
四、运行文件和使用方法
此文件的使用方式比较特殊,我们首先需要配置好其中的参数(第一次适用建议大家用官方的权重文件),配置好之后我们需要通过命令行(终端)通过python 你给文件起的名字.py 的方式运行!!!注意不通过这种方式会报错!!
shell
python 你给文件起的名字.py看下图大家就知道如何使用了。
我的默认参数都在代码中,大家可以看到我用的都是官方默认的,在3070上FPS可以达到170+(具体高低和你的设备有关,大家发论文的适合也要标明自己的实验设备,然后在相同的实验设备上改进的模型和基础模型的FPS提供了多少。)
五、效果展示
下面是效果展示,可以看到所有的参数均已打印。
