

 louaq
louaq 
1959 字
10 分钟
代码复现记录BSAFusion
癌症影像档案馆下载脚本(TICA)
import requestsimport osimport timeimport jsonimport zipfilefrom urllib.parse import urlencode
class TCIADownloader: def __init__(self): self.session = requests.Session() self.session.headers.update({ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' })
def read_manifest(self, manifest_file): """读取manifest文件""" with open(manifest_file, 'r') as f: lines = f.readlines()
config = {} series_list = []
for line in lines: line = line.strip() if '=' in line and not line.startswith('1.3.6.1.4.1.14519'): key, value = line.split('=', 1) config[key] = value elif line.startswith('1.3.6.1.4.1.14519'): series_list.append(line)
return config, series_list
def try_method_1_nbia_servlet(self, series_uid, download_dir): """方法1: 使用NBIA servlet""" print(f" 方法1: NBIA Servlet")
url = "https://nbia.cancerimagingarchive.net/nbia-download/servlet/DownloadServlet"
param_combinations = [ {'annotation': 'true', 'series': series_uid}, {'includeAnnotation': 'true', 'series': series_uid}, {'seriesInstanceUID': series_uid}, {'SeriesInstanceUID': series_uid, 'format': 'zip'}, ]
for i, params in enumerate(param_combinations): try: print(f" 尝试参数组合 {i+1}/{len(param_combinations)}")
response = self.session.get(url, params=params, stream=True, timeout=120)
if response.status_code == 200: filename = f"{series_uid}_method1.zip" filepath = os.path.join(download_dir, filename)
total_size = int(response.headers.get('content-length', 0))
with open(filepath, 'wb') as f: downloaded = 0 for chunk in response.iter_content(chunk_size=8192): if chunk: f.write(chunk) downloaded += len(chunk)
if total_size > 0: progress = (downloaded / total_size) * 100 print(f"\r 下载进度: {progress:.1f}%", end='')
print(f"\r 下载完成: {downloaded} bytes")
if downloaded > 1000: # 至少1KB return True, filepath else: os.remove(filepath)
except Exception as e: print(f" 错误: {e}") continue
return False, None
def try_method_2_tcia_api(self, series_uid, download_dir): """方法2: 使用TCIA REST API""" print(f" 方法2: TCIA REST API")
url = "https://services.cancerimagingarchive.net/services/v4/TCIA/query/getImage"
param_combinations = [ {'SeriesInstanceUID': series_uid, 'format': 'zip'}, {'SeriesInstanceUID': series_uid}, {'series': series_uid, 'format': 'zip'}, ]
for i, params in enumerate(param_combinations): try: print(f" 尝试API参数组合 {i+1}/{len(param_combinations)}")
response = self.session.get(url, params=params, stream=True, timeout=300)
if response.status_code == 200: filename = f"{series_uid}_method2.zip" filepath = os.path.join(download_dir, filename)
total_size = int(response.headers.get('content-length', 0))
with open(filepath, 'wb') as f: downloaded = 0 for chunk in response.iter_content(chunk_size=8192): if chunk: f.write(chunk) downloaded += len(chunk)
if total_size > 0: progress = (downloaded / total_size) * 100 print(f"\r 下载进度: {progress:.1f}%", end='')
print(f"\r 下载完成: {downloaded} bytes")
if downloaded > 1000: return True, filepath else: os.remove(filepath)
elif response.status_code == 404: print(f" 系列未找到 (404)") break elif response.status_code == 401: print(f" 需要身份验证 (401)") break else: print(f" HTTP错误: {response.status_code}")
except Exception as e: print(f" API错误: {e}") continue
return False, None
def try_method_3_direct_dicom(self, series_uid, download_dir): """方法3: 尝试直接DICOM下载""" print(f" 方法3: 直接DICOM下载")
# 首先获取系列中的图像列表 try: url = "https://services.cancerimagingarchive.net/services/v4/TCIA/query/getSOPInstanceUIDs" params = {'SeriesInstanceUID': series_uid, 'format': 'json'}
response = self.session.get(url, params=params, timeout=60)
if response.status_code == 200: sop_instances = response.json()
if sop_instances and len(sop_instances) > 0: print(f" 找到 {len(sop_instances)} 个DICOM实例")
# 创建系列目录 series_dir = os.path.join(download_dir, f"{series_uid}_dicom") if not os.path.exists(series_dir): os.makedirs(series_dir)
downloaded_count = 0
# 下载前几个实例作为测试 for i, instance in enumerate(sop_instances[:3]): # 只下载前3个作为测试 sop_uid = instance.get('SOPInstanceUID', '') if sop_uid: success = self.download_single_dicom(series_uid, sop_uid, series_dir) if success: downloaded_count += 1
if i >= 2: # 只测试前3个 break
if downloaded_count > 0: print(f" 成功下载 {downloaded_count} 个DICOM文件") return True, series_dir
except Exception as e: print(f" DICOM下载错误: {e}")
return False, None
def download_single_dicom(self, series_uid, sop_uid, series_dir): """下载单个DICOM文件""" try: url = "https://services.cancerimagingarchive.net/services/v4/TCIA/query/getImage" params = { 'SeriesInstanceUID': series_uid, 'SOPInstanceUID': sop_uid }
response = self.session.get(url, params=params, stream=True, timeout=120)
if response.status_code == 200: filename = f"{sop_uid}.dcm" filepath = os.path.join(series_dir, filename)
with open(filepath, 'wb') as f: for chunk in response.iter_content(chunk_size=8192): if chunk: f.write(chunk)
if os.path.getsize(filepath) > 100: # 至少100字节 return True else: os.remove(filepath)
except Exception as e: print(f" 单个DICOM下载错误: {e}")
return False
def test_download_methods(self, series_list, download_dir, test_count=3): """测试不同的下载方法""" print(f"\n测试前 {test_count} 个系列的下载方法...")
working_methods = []
for i, series_uid in enumerate(series_list[:test_count]): print(f"\n测试系列 {i+1}/{test_count}: {series_uid}")
# 方法1: NBIA Servlet success, filepath = self.try_method_1_nbia_servlet(series_uid, download_dir) if success: working_methods.append(('method1', filepath)) print(f" ✓ 方法1 成功") continue
# 方法2: TCIA API success, filepath = self.try_method_2_tcia_api(series_uid, download_dir) if success: working_methods.append(('method2', filepath)) print(f" ✓ 方法2 成功") continue
# 方法3: 直接DICOM success, filepath = self.try_method_3_direct_dicom(series_uid, download_dir) if success: working_methods.append(('method3', filepath)) print(f" ✓ 方法3 成功") continue
print(f" ✗ 所有方法都失败")
return working_methods
def download_all_series(self, series_list, download_dir, working_method): """使用找到的有效方法下载所有系列""" print(f"\n使用方法 {working_method} 下载所有 {len(series_list)} 个系列...")
successful_downloads = 0 failed_downloads = 0
for i, series_uid in enumerate(series_list): print(f"\n下载系列 {i+1}/{len(series_list)}: {series_uid}")
success = False
if working_method == 'method1': success, _ = self.try_method_1_nbia_servlet(series_uid, download_dir) elif working_method == 'method2': success, _ = self.try_method_2_tcia_api(series_uid, download_dir) elif working_method == 'method3': success, _ = self.try_method_3_direct_dicom(series_uid, download_dir)
if success: successful_downloads += 1 print(f" ✓ 下载成功") else: failed_downloads += 1 print(f" ✗ 下载失败")
# 添加延迟避免服务器过载 time.sleep(2)
print(f"\n=== 下载完成统计 ===") print(f"成功: {successful_downloads}") print(f"失败: {failed_downloads}") print(f"总计: {len(series_list)}")
return successful_downloads, failed_downloads
def extract_zip_files(self, download_dir, extract_dir="tcia_extracted"): """解压下载的ZIP文件""" if not os.path.exists(extract_dir): os.makedirs(extract_dir)
zip_files = [f for f in os.listdir(download_dir) if f.endswith('.zip')]
if not zip_files: print("没有找到ZIP文件") return
print(f"\n解压 {len(zip_files)} 个ZIP文件...")
for zip_file in zip_files: zip_path = os.path.join(download_dir, zip_file) extract_path = os.path.join(extract_dir, zip_file[:-4])
try: with zipfile.ZipFile(zip_path, 'r') as zip_ref: zip_ref.extractall(extract_path) print(f"✓ 解压完成: {zip_file}") except Exception as e: print(f"✗ 解压失败 {zip_file}: {e}")
def main(): """主函数""" manifest_file = "Vestibular-Schwannooma-MC-RC manifest August 2023.tcia" download_dir = "tcia_downloads" extract_dir = "tcia_extracted"
print("TCIA数据下载器 v3.0") print("=" * 60)
# 检查manifest文件 if not os.path.exists(manifest_file): print(f"错误: 找不到manifest文件: {manifest_file}") print("请确保manifest文件在当前目录下") return
# 创建下载目录 if not os.path.exists(download_dir): os.makedirs(download_dir)
try: # 初始化下载器 downloader = TCIADownloader()
# 读取manifest文件 config, series_list = downloader.read_manifest(manifest_file) print(f"从manifest文件读取到 {len(series_list)} 个系列")
if not series_list: print("错误: manifest文件中没有找到系列UID") return
# 测试下载方法 working_methods = downloader.test_download_methods(series_list, download_dir, test_count=3)
if not working_methods: print("\n❌ 所有下载方法都失败了") print("可能的原因:") print("1. 网络连接问题") print("2. TCIA服务器暂时不可用") print("3. 需要登录TCIA账户") print("4. 数据集可能已被移除或限制访问") return
print(f"\n✅ 找到 {len(working_methods)} 种有效的下载方法")
# 选择最佳方法 best_method = working_methods[0][0] # 使用第一个成功的方法
# 询问是否继续下载所有文件 choice = input(f"\n是否使用找到的方法下载所有 {len(series_list)} 个系列? (y/n): ").lower().strip()
if choice == 'y': successful, failed = downloader.download_all_series(series_list, download_dir, best_method)
if successful > 0: # 询问是否解压文件 extract_choice = input(f"\n成功下载了 {successful} 个文件。是否解压ZIP文件? (y/n): ").lower().strip() if extract_choice == 'y': downloader.extract_zip_files(download_dir, extract_dir) print(f"\n文件已解压到: {extract_dir}")
print(f"\n✅ 下载完成!") print(f"📁 下载目录: {download_dir}") if extract_choice == 'y': print(f"📁 解压目录: {extract_dir}") else: print("\n❌ 没有成功下载任何文件") else: print("下载已取消")
except KeyboardInterrupt: print("\n\n⚠️ 下载被用户中断") except Exception as e: print(f"\n❌ 发生未知错误: {e}") import traceback traceback.print_exc()
def show_help(): """显示帮助信息""" help_text = """TCIA数据下载器使用说明:
1. 准备工作: - 将TCIA manifest文件保存为 'manifest-1692206474218.tcia' - 确保网络连接正常 - 安装Python依赖: pip install requests
2. 运行方式: python tcia_downloader.py
3. 下载过程: - 程序会自动测试多种下载方法 - 找到有效方法后会询问是否继续下载全部文件 - 下载完成后可选择是否解压文件
4. 输出目录: - tcia_downloads/ : 下载的原始文件 - tcia_extracted/ : 解压后的DICOM文件
5. 注意事项: - 医学影像文件通常很大,确保有足够磁盘空间 - 下载可能需要很长时间,请保持网络连接稳定 - 如果某些文件下载失败,可以重新运行程序(会跳过已下载的文件)
6. 故障排除: - 如果所有方法都失败,可能需要先登录TCIA网站 - 检查防火墙设置是否阻止了连接 - 尝试使用VPN或更换网络环境""" print(help_text)
def check_dependencies(): """检查依赖项""" try: import requests return True except ImportError: print("❌ 缺少依赖项: requests") print("请运行: pip install requests") return False
def check_disk_space(download_dir, estimated_size_gb=50): """检查磁盘空间""" try: import shutil free_space = shutil.disk_usage(download_dir)[2] / (1024**3) # GB
if free_space < estimated_size_gb: print(f"⚠️ 磁盘空间可能不足") print(f"可用空间: {free_space:.1f} GB") print(f"预估需要: {estimated_size_gb} GB") choice = input("是否继续? (y/n): ").lower().strip() return choice == 'y' else: print(f"✅ 磁盘空间充足: {free_space:.1f} GB") return True except: return True
def create_download_summary(download_dir, series_list, successful_count, failed_count): """创建下载摘要文件""" summary_file = os.path.join(download_dir, "download_summary.txt")
try: with open(summary_file, 'w', encoding='utf-8') as f: f.write("TCIA数据下载摘要\n") f.write("=" * 50 + "\n\n") f.write(f"下载时间: {time.strftime('%Y-%m-%d %H:%M:%S')}\n") f.write(f"总系列数: {len(series_list)}\n") f.write(f"成功下载: {successful_count}\n") f.write(f"失败数量: {failed_count}\n") f.write(f"成功率: {(successful_count/len(series_list)*100):.1f}%\n\n")
# 列出下载的文件 downloaded_files = [f for f in os.listdir(download_dir) if f.endswith('.zip') or f.endswith('.dcm')]
if downloaded_files: f.write("已下载文件列表:\n") f.write("-" * 30 + "\n") for file in sorted(downloaded_files): file_path = os.path.join(download_dir, file) file_size = os.path.getsize(file_path) / (1024*1024) # MB f.write(f"{file:<50} {file_size:>8.1f} MB\n")
print(f"📋 下载摘要已保存到: {summary_file}")
except Exception as e: print(f"⚠️ 无法创建下载摘要: {e}")
if __name__ == "__main__": import sys
# 检查命令行参数 if len(sys.argv) > 1: if sys.argv[1] == '--help' or sys.argv[1] == '-h': show_help() sys.exit(0)
# 检查依赖项 if not check_dependencies(): sys.exit(1)
# 运行主程序 main()训练截图


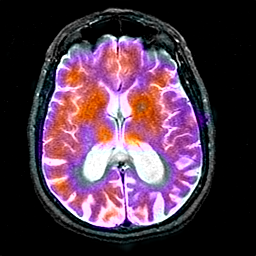
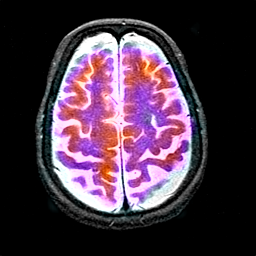
融合结果
CT-MRI


PET-MRI


SPECT-MRI
代码复现记录BSAFusion
https://louaq.github.io/posts/multimodal/代码复现记录_bsafusion/ 最后更新于 2025-08-01,距今已过 135 天
部分内容可能已过时