
大连大学、北京科技大学、大连理工大学、阿尔斯特大学
摘要
Multi-modality image fusion (MMIF) entails synthesizing images with detailed textures and prominent objects. Existing methods tend to use general feature extraction to handle different fusion tasks. However, these methods have difficulty breaking fusion barriers across various modalities owing to the lack of targeted learning routes. In this work, we propose a multi-scenario feature joint learning architecture, MLFuse, that employs the commonalities of multi-modality images to deconstruct the fusion progress. Specifically, we construct a cross-modal knowledge reinforcing network that adopts a multipath calibration strategy to promote information communication between different images. In addition, two professional networks are developed to maintain the salient and textural information of fusion results. The spatial-spectral domain optimizing network can learn the vital relationship of the source image context with the help of spatial attention and spectral attention. The edge-guided learning network utilizes the convolution operations of various receptive fields to capture image texture information. The desired fusion results are obtained by aggregating the outputs from the three networks. Extensive experiments demonstrate the superiority of MLFuse for infrared-visible image fusion and medical image fusion. The excellent results of downstream tasks (i.e., object detection and semantic segmentation) further verify the high-quality fusion performance of our method. The code is publicly available at https://github.com/jialei-sc/MLFuse
翻译
多模态图像融合(MMIF)涉及合成具有详细纹理和突出物体的图像。现有方法倾向于使用通用特征提取来处理不同的融合任务。然而,由于缺乏针对性的学习路径,这些方法难以突破各种模态间的融合障碍。在这项工作中,我们提出了一种多场景特征联合学习架构,MLFuse,该架构利用多模态图像的共性来解构融合过程。具体而言,我们构建了一个跨模态知识增强网络,采用多路径校准策略以促进不同图像间的信息交流。此外,开发了两个专业网络以保持融合结果的显著信息和纹理信息。空间-光谱域优化网络可以借助空间注意力和光谱注意力学习源图像上下文的重要关系。边缘引导学习网络利用各种感受野的卷积操作来捕获图像纹理信息。通过聚合三个网络的输出获得期望的融合结果。大量实验表明,MLFuse在红外-可见光图像融合和医学图像融合方面的优越性。后续任务(如目标检测和语义分割)的出色结果进一步验证了我们方法的高质量融合性能。代码公开于 https://github.com/jialei-sc/MLFuse
研究背景
多模态图像融合(MMIF)旨在合成具有详细纹理和突出对象的图像,典型任务包括红外-可见图像融合(IVIF)和医学图像融合(MIF)。现有MMIF方法主要分为非生成模型和生成模型两类,但存在明显缺陷:
- 多数统一融合方法忽视传感器成像机制差异,未区分单模态与多模态任务。
- 缺乏专门学习策略,无法有效引导网络掌握多种融合任务优势。
- 通用特征提取难以同时保留源图像的前景显著对象和背景纹理细节。
因此,本文旨在探索更合理的融合架构,建立统一的多模态图像融合网络以执行IVIF和MIF任务。但面临两个挑战:一是如何有效学习多场景的关键知识,二是如何进行模型优化。为解决这些问题,作者提出多场景特征联合学习架构MLFuse,通过三个有针对性的任务打破不同模态间的融合障碍。
研究现状
- 基于非生成模型方法(non-generative models):包括自动编码器(AE)、卷积神经网络(CNN)和Transformer(TF)。AE需在大数据集训练后提取特征,常采用手工设计融合策略;CNN构建网络结构与损失函数实现隐式特征学习;TF利用自注意力机制捕捉长程依赖。
- 基于生成模型方法 (generative models):主要有生成对抗网络(GAN)和扩散模型(DM)。GAN能学习图像强度与细节分布,但训练易模态失衡;DM克服了GAN训练不稳定问题,在图像融合中有出色表现。
- 多任务学习:可高效优化模型多目标函数,常直接相加多个损失函数权重,也有算法自动调整损失权重。
提出的模型
模型的统一公式:
式中,$L_f$为结构相似损失,$F$为具有可学习参数ωf的多模态图像重构网络。$F$的网络结构如图图所示。$λ$是权衡参数。$x$为结构图像,包括可见光和MRI图像,$y$为功能图像,包括红外、SPECT、CT、PET图像。$u_Ψ$、$u_Φ$和$u_Υ$表示T的三个结果,T由三个网络组成(即跨模态知识强化网络Ψ、空间-频谱域优化网络Υ和边缘引导学习网络Φ)。这是一个混合损失,包括LΨ, LΥ和LΦ。ωt是关于T的一些可训练参数。
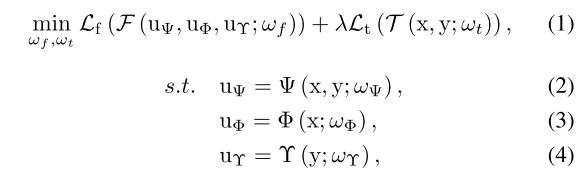
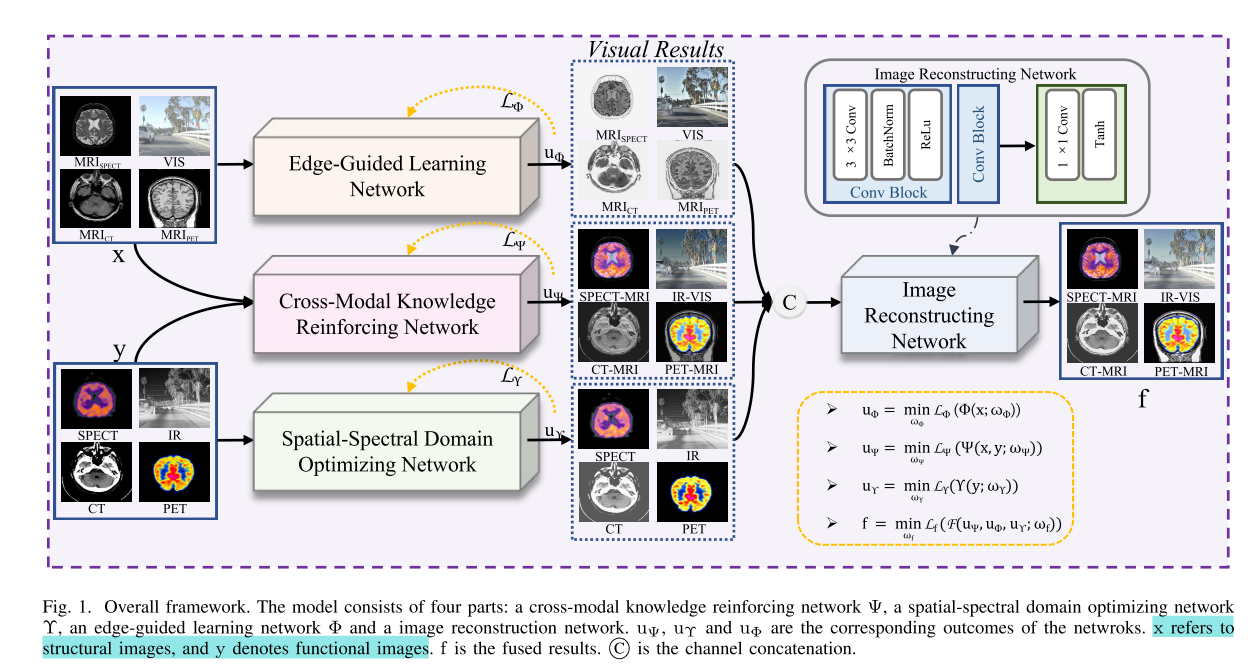
本文提出了一种多场景特征联合学习架构MLFuse,旨在解决多模态图像融合(MMIF)中的问题,实现红外 - 可见光图像融合(IVIF)和医学图像融合(MIF)任务。其主要由以下部分构成:
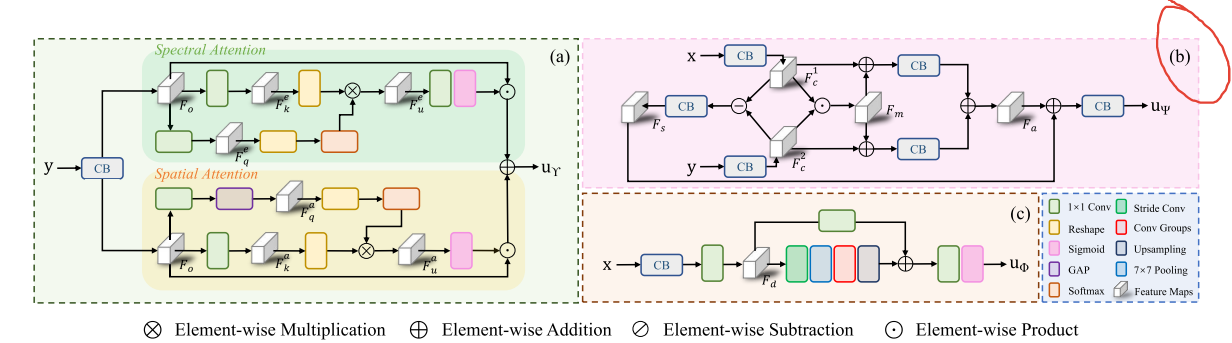
- 交叉模态知识增强网络:基于源图像的一致特征和差异特征,提出此网络以充分利用互补信息实现特征聚合。通过构建多路径校准策略,从特征一致性和特征差异的角度强化源图像的特征关系,增强多模态之间的信息交互。
- 空间 - 光谱域优化网络:该优化网络由光谱注意力子网络和空间注意力子网络组成,用于强化融合结果中的显著上下文。光谱注意力优化子网络从光谱方面细化特征,获取各通道权重因子以重新校准原始特征;空间注意力优化子网络从空间角度处理特征,得到空间特征各坐标的加权因子来重新校准初始特征图,最后将两个子网络的输出相加聚合相关特征。
- 边缘引导学习网络:此网络能够从可见光图像和MRI图像中高效获取纹理特征。对输入图像进行卷积操作后,通过特殊卷积、池化、卷积组及上采样等操作,从不同路径处理特征,最后将两路结果相加并经Sigmoid函数输出。
- 图像重建网络:利用多模态图像的共性,将特征学习阶段分解为三个有针对性的任务,有效提取和合并结构图像的纹理细节与功能图像的显著特征,再通过该网络合成具有美感的融合结果。
- 损失函数:主要分为两部分,第一部分是结构相似性损失,用于优化整个网络,平衡网络学习能力,帮助模型学习源图像的结构元素;第二部分由三个优化损失组成,分别对应交叉模态知识增强网络、空间 - 光谱域优化网络和边缘引导学习网络,通过不同的损失计算方式,使各网络专注于学习相应的特征。
实验(Compared with SOTA)
数据集:针对红外与可见光图像融合(IVIF)任务,采用RoadScene进行训练和验证,M3FD和MSRS用于测试;针对医学图像融合(MIF)任务,在Harvard1数据集上开展,按一定比例划分训练集、验证集与测试集。
训练细节:基于特定CPU和GPU,在Pytorch框架下训练500个epoch,数据随机裁剪为128×128的补丁,设置批大小、学习率等参数,训练前将图像转换到Y通道。
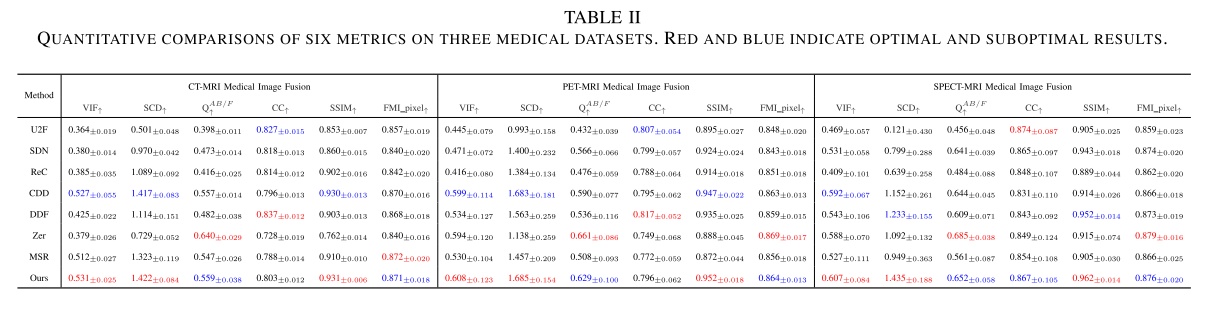
评估指标:采用视觉信息保真度(VIF)、相关差异总和(SCD)、QAB/F、相关系数(CC)、结构相似性(SSIM)、特征互信息(FMI pixel)六种指标衡量融合效果。
对比方法:引入五种通用融合方法、四种专门融合方法与MLFuse对比。
- IVIF实验:
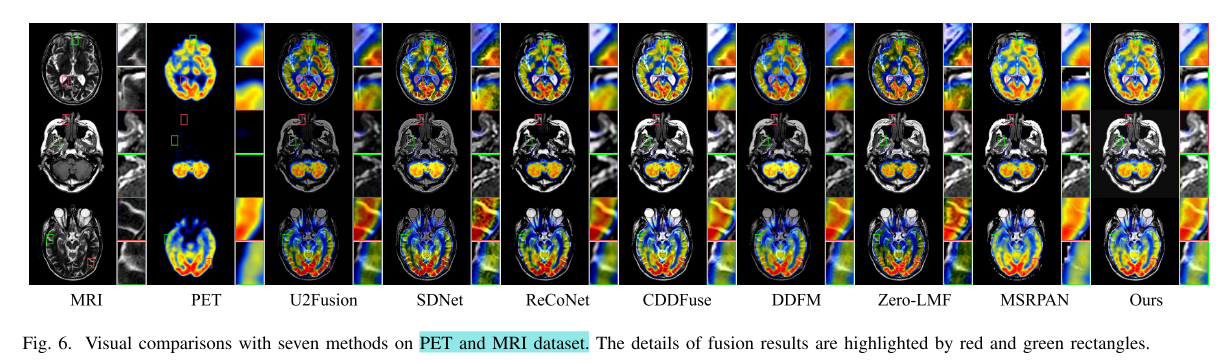
- 定性比较:在MSRS和M3FD数据集上对比,通过可视化展示,发现MLFuse在捕捉场景纹理和前景物体细节方面优于其他方法。
- 定量比较:运用六种指标从多视角分析,结果表明MLFuse在部分指标上表现最佳,具有显著的泛化能力。
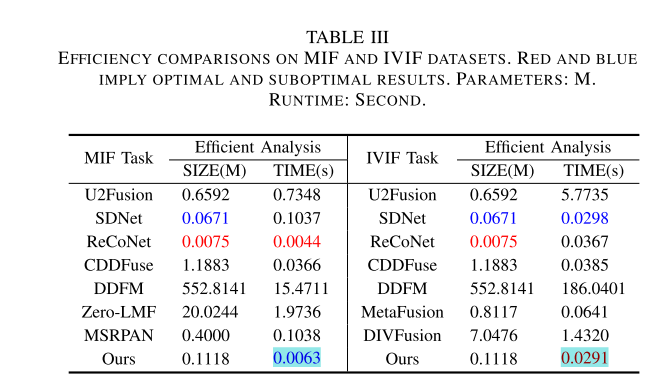
- 效率评估:量化各方法融合效率,MLFuse模型大小适中且融合速率最佳。



- MIF实验:
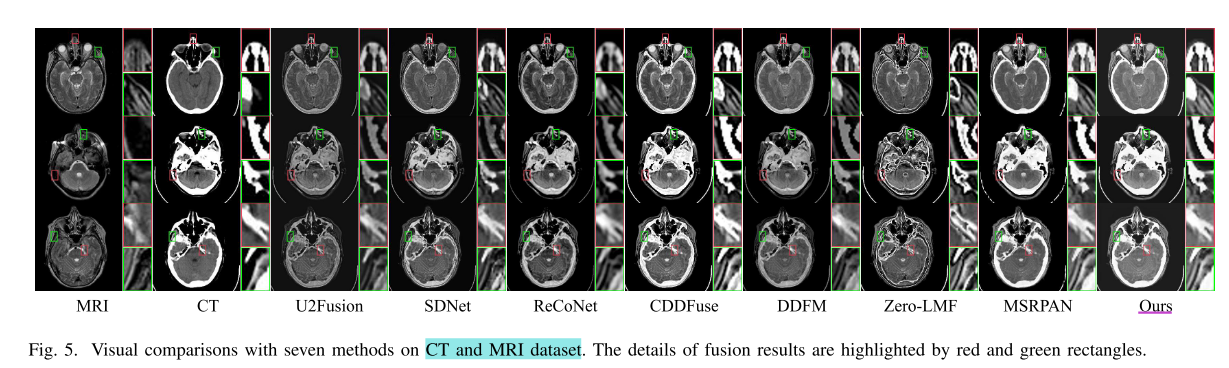
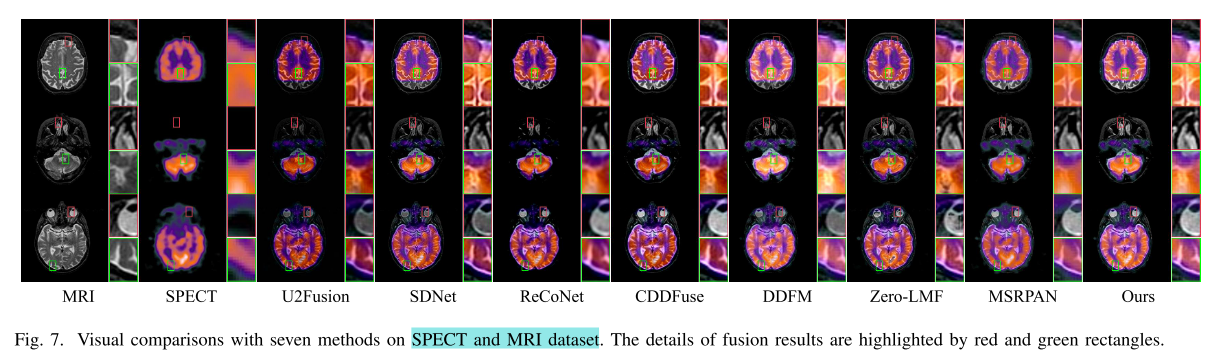
- 定性比较:在Harvard数据集上对CT - MRI、PET - MRI和SPECT - MRI三种任务对比,MLFuse融合结果能更好恢复结构和显著元素。
- 定量比较:结果显示MLFuse在多个指标上表现出色,实现了主观与客观评价的统一。
- 效率评估:对比多种模型的融合效率和参数,MLFuse参数第三小,运行时间第二短,对不同分辨率图像有稳定表现。
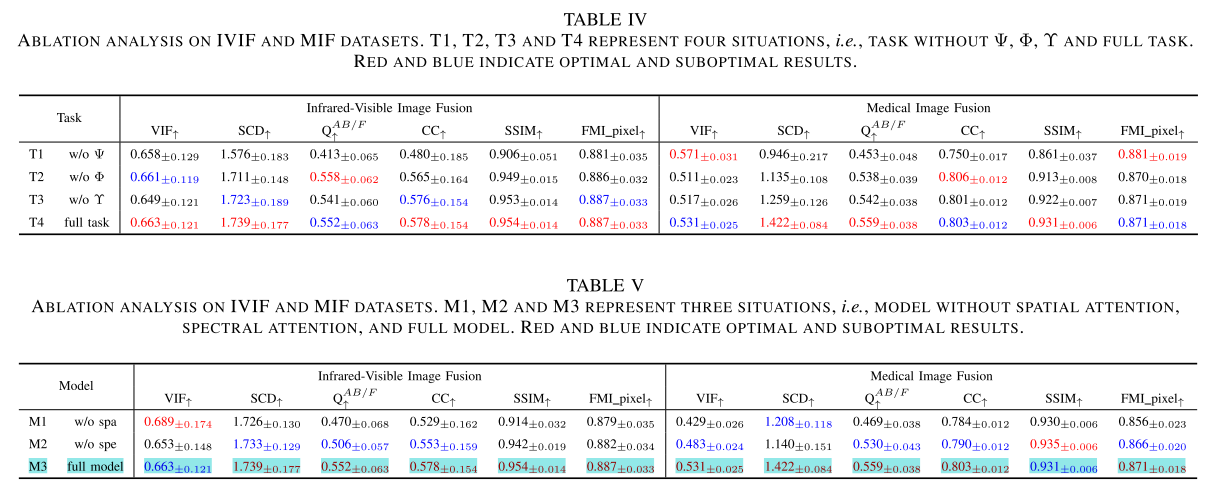
实验(Ablation Experiments)
- 子任务讨论:替换网络为卷积块,通过可视化和指标分析表明三个网络对理想融合性能都至关重要,同时应用时融合结果更稳定。
- 子模块讨论:验证空间 - 光谱域优化网络性能,结果表明同时使用空间和光谱注意力块能使模型获得最大收益。
- 损失讨论:验证LΨ、LΥ和LΦ对模型的作用,完整损失配置可获得更符合人眼视觉且纹理结构丰富的融合结果,确定了超参数的最优配置。
IVIF(红外-可见图像融合)下游应用实验
- 红外 - 可见光目标检测:在M3FD数据集上用YOLOv5检测,通过可视化和mAP@0.5指标评估,MLFuse能提升检测准确性。
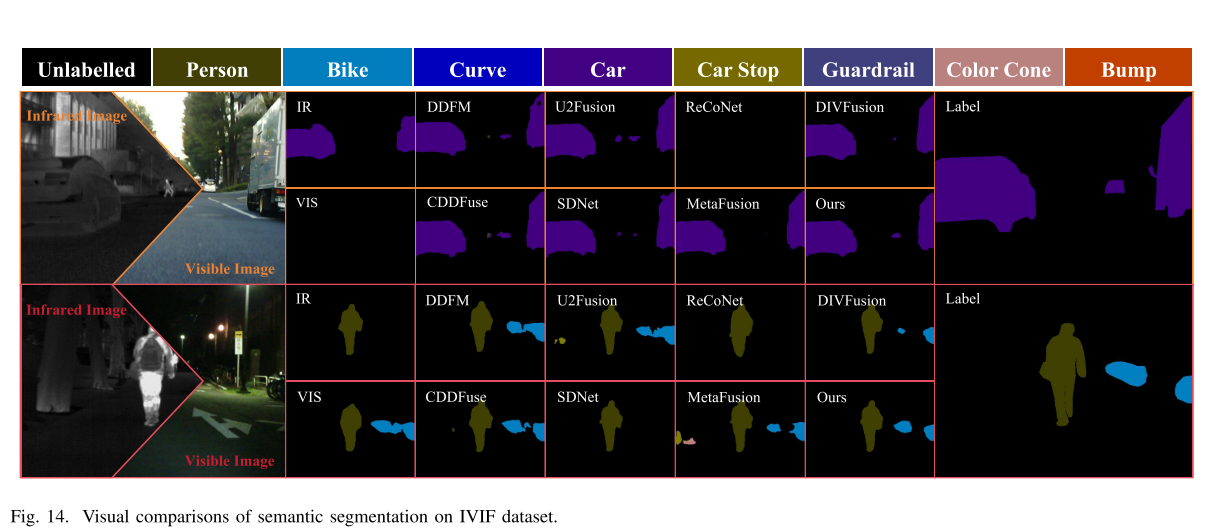
- 红外 - 可见光语义分割:在MSRS数据集上用DeeplabV3+分割,以交并比(IoU)衡量,可视化和定量结果表明MLFuse可生成高质量融合图像,但部分目标分数低于原始输入,可能因数据集类别不足和模型对红外数据适配不佳。

结论
作者提出一种多场景特征联合学习架构MLFuse,将融合过程分解为三个任务,各构建可学习网络。经对比与消融实验,得出以下结论:该架构具备高质量融合效果。其中,跨模态知识强化网络通过多路径校准策略加强特征关系,实现图像间有效信息交流;空间 - 光谱域优化网络借助空间与光谱注意力增强融合结果的显著物体;边缘引导学习网络提升模型纹理捕捉能力;图像重建网络生成理想融合结果。此外,下游任务(目标检测和语义分割)结果进一步验证了其在红外 - 可见图像融合任务中的性能。不过,MLFuse基于空间严格对齐数据,未来期望开发结合图像配准与融合的鲁棒算法。




