
南华大学
摘要
Multimodal medical image fusion aims to integrate complementary information from different modalities of medical images. Deep learning methods, especially recent vision Transformers, have effectively improved image fusion performance. However, there are limitations for Transformers in image fusion, such as lacks of local feature extraction and cross-modal feature interaction, resulting in insufficient multimodal feature extraction and integration. In addition, the computational cost of Transformers is higher. To address these challenges, in this work, we develop an adaptive cross-modal fusion strategy for unsupervised multimodal medical image fusion. Specifically, we propose a novel lightweight cross Transformer based on cross multi-axis attention mechanism. It includes cross-window attention and cross-grid attention to mine and integrate both local and global interactions of multimodal features. The cross Transformer is further guided by a spatial adaptation fusion module, which allows the model to focus on the most relevant information. Moreover, we design a special feature extraction module that combines multiple gradient residual dense convolutional and Transformer layers to obtain local features from coarse to fine and capture global features. The proposed strategy significantly boosts the fusion performance while minimizing computational costs. Extensive experiments, including clinical brain tumor image fusion, have shown that our model can achieve clearer texture details and better visual quality than other state-of-the-art fusion methods.
翻译
多模态医学图像融合旨在整合来自不同医学图像模态的互补信息。深度学习方法,尤其是近期的视觉Transformer,有效提升了图像融合性能。然而,Transformer在图像融合中存在局限性,例如缺乏局部特征提取和跨模态特征交互,导致多模态特征提取和整合不够充分。此外,Transformer的计算成本较高。为了解决这些挑战,本研究开发了一种用于无监督多模态医学图像融合的自适应跨模态融合策略。具体而言,我们提出了一种基于跨多轴注意机制的新型轻量级跨Transformer。它包括跨窗口注意和跨网格注意,以挖掘和整合多模态特征的局部和全局交互。跨Transformer进一步由空间适应融合模块引导,使模型能够聚焦于最相关的信息。此外,我们设计了一个特殊的特征提取模块,该模块结合了多个梯度残差密集卷积层和Transformer层,以从粗到细获取局部特征并捕获全局特征。所提出的策略在显著提升融合性能的同时,最小化了计算成本。大量实验,包括临床脑肿瘤图像融合,表明我们的模型能够比其他先进融合方法实现更清晰的纹理细节和更好的视觉质量。
研究背景
多模态医学影像在疾病诊断中至关重要,但不同模态影像各有优劣。结构影像(如CT、MRI)空间分辨率高,能展现器官解剖结构,但CT缺乏结构组织细节信息,MRI缺乏高对比度信息;功能影像(如PET、SPECT)可反映生物分子血流和代谢活动,但空间分辨率低。多模态影像融合旨在整合不同影像的互补信息,增强视觉感知。
现有的医学影像融合方法分为经典方法和深度学习方法。经典方法存在不可逆数据丢失、细节失真、融合规则设计复杂等问题;深度学习方法虽有优势,但CNN框架会忽略长程交互,导致全局上下文特征丢失,而Transformer方法存在局部特征提取和跨模态特征交互不足、计算成本高等问题。
受 Vision Transformer成功应用的启发,本文提出一种自适应跨模态融合策略,开发了轻量级的MACTFusion跨Transformer架构,旨在以较低计算成本挖掘和整合多模态特征的局部和全局交互,提高融合性能,为后续疾病诊断、治疗规划和手术导航等提供更有价值的影像信息。
研究现状
- 多模态医学成像重要性:多模态医学成像在疾病诊断中发挥关键作用,医学图像分为结构和功能信息图像两类,不同成像方式各有优劣,图像融合可整合互补信息。
- 融合方法分类:现有医学图像融合方法分为经典方法和深度学习方法。经典方法包括多尺度变换、脉冲耦合神经网络和稀疏表示等,但存在不可逆数据损失和细节失真等问题。深度学习方法主要有卷积神经网络(CNNs)、生成对抗网络(GANs)和Transformers等,在融合性能上有提升,但仍有局限。
- Transformer应用:Transformer在医学图像融合中得到应用,如SwinFusion等,但多数网络融合策略简单,无法充分挖掘和整合跨模态信息,且计算成本高。
提出的模型
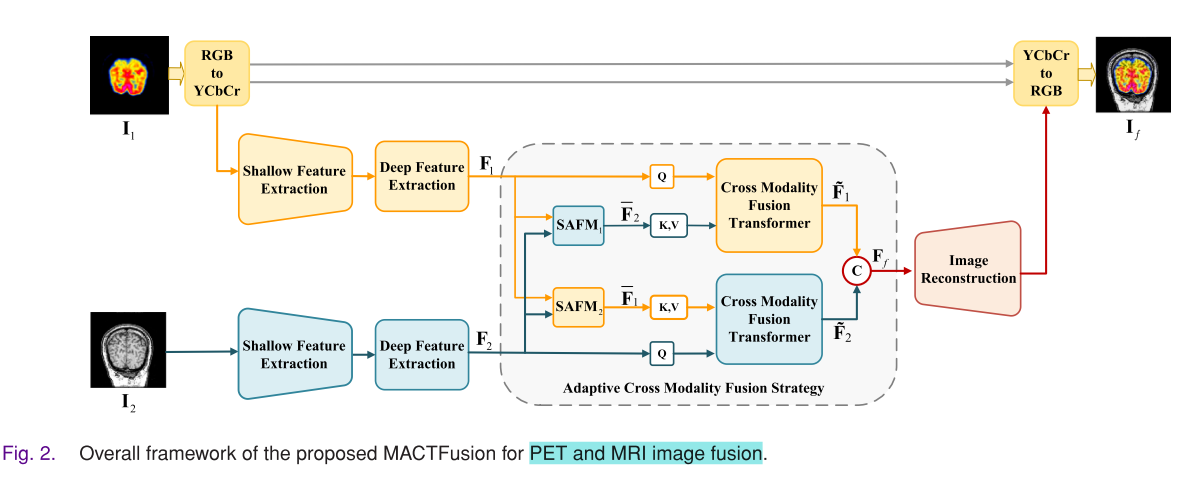
模型主要聚焦于MRI与其他医学图像(如CT、PET和SPECT图像)的融合,包含特征提取、自适应跨模态融合和图像重建三个部分:
- 特征提取
- 浅层特征提取:由密集特征提取器和梯度密集块(GRDB)组成。密集特征提取器通过1×1卷积降低通道维度,再用三个级联的3×3卷积层提取局部特征并拼接输出。GRDB则通过梯度操作增强对细粒度细节的学习。
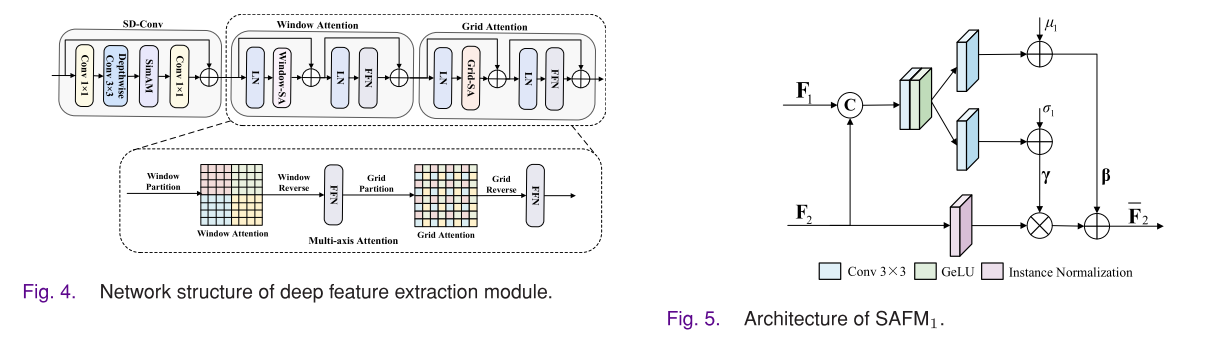
- 深层特征提取:由简单深度可分离卷积(SD - Conv)块和多轴注意力块构成。SD - Conv块可作为位置编码生成器,使模型无需显式的位置编码层。多轴注意力块由窗口注意力和网格注意力组成,可降低计算复杂度,同时获取局部和全局交互信息。
- 自适应跨模态融合策略
- 空间自适应融合模块(SAFM):基于空间自适应归一化思想,可自适应地重新映射特征分布,使模型学习到丰富的纹理和合适的强度信息。
- 跨模态融合Transformer:包括跨窗口注意力和跨网格注意力,用于挖掘和整合多模态特征的局部和全局交互。输入特征先经过SD - Conv块处理,再通过跨窗口注意力进行局部交互,接着通过跨网格注意力进行全局交互,最后将两个对称分支的输出特征拼接得到最终的融合特征。
- 图像重建:通过图像重建模块从融合特征中重建融合图像。
损失函数
综合考虑多个方面定义了联合损失函数,包括结构相似性指数损失(SSIM)、梯度损失(纹理损失)和强度损失,以保证融合图像的视觉保真度和强度信息。公式为:$L = \delta_1L_{ssim} + \delta_2L_{grad} + \delta_3L_{int}$,其中$\delta_1$、$\delta_2$和$\delta_3$是控制各损失项权重的参数。
实验(Compared with SOTA)
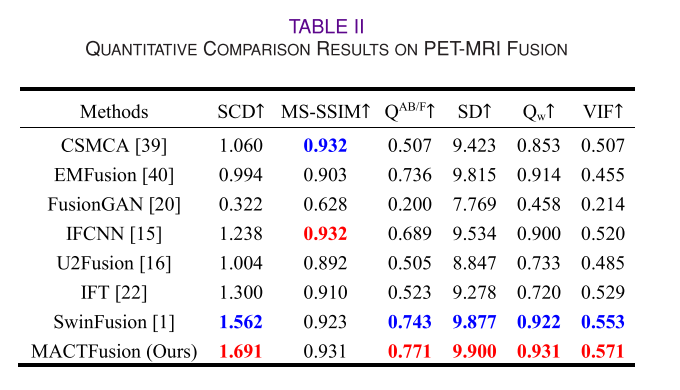
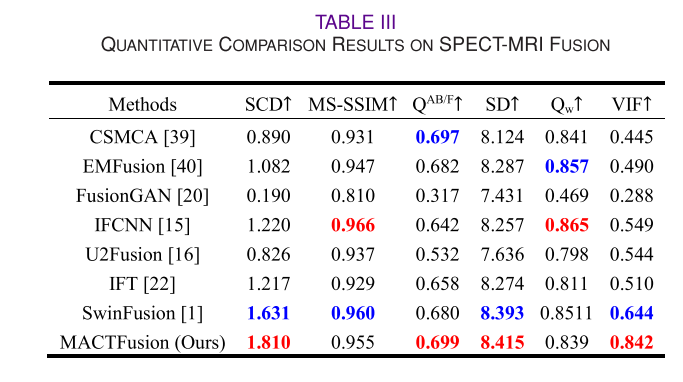
对比实验与评估指标:
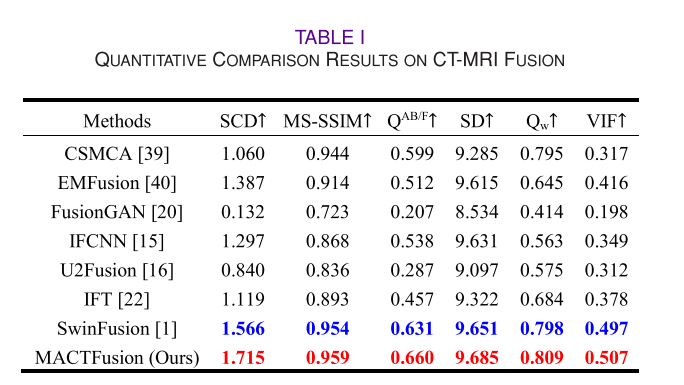
- 对比方法:与CSMCA、EMFusion、FusionGAN、IFCNN、U2Fusion、IFT和SwinFusion等先进方法进行对比。
- 评估指标:选用了包括相关差异之和(SCD)、多尺度结构相似性指数(MS - SSIM)、边缘信息测量(QAB/F)、标准差(SD)、加权融合质量指标(Qw)和视觉信息保真度(VIF)在内的六个常见定量指标进行评估。
不同模态医学图像融合实验:
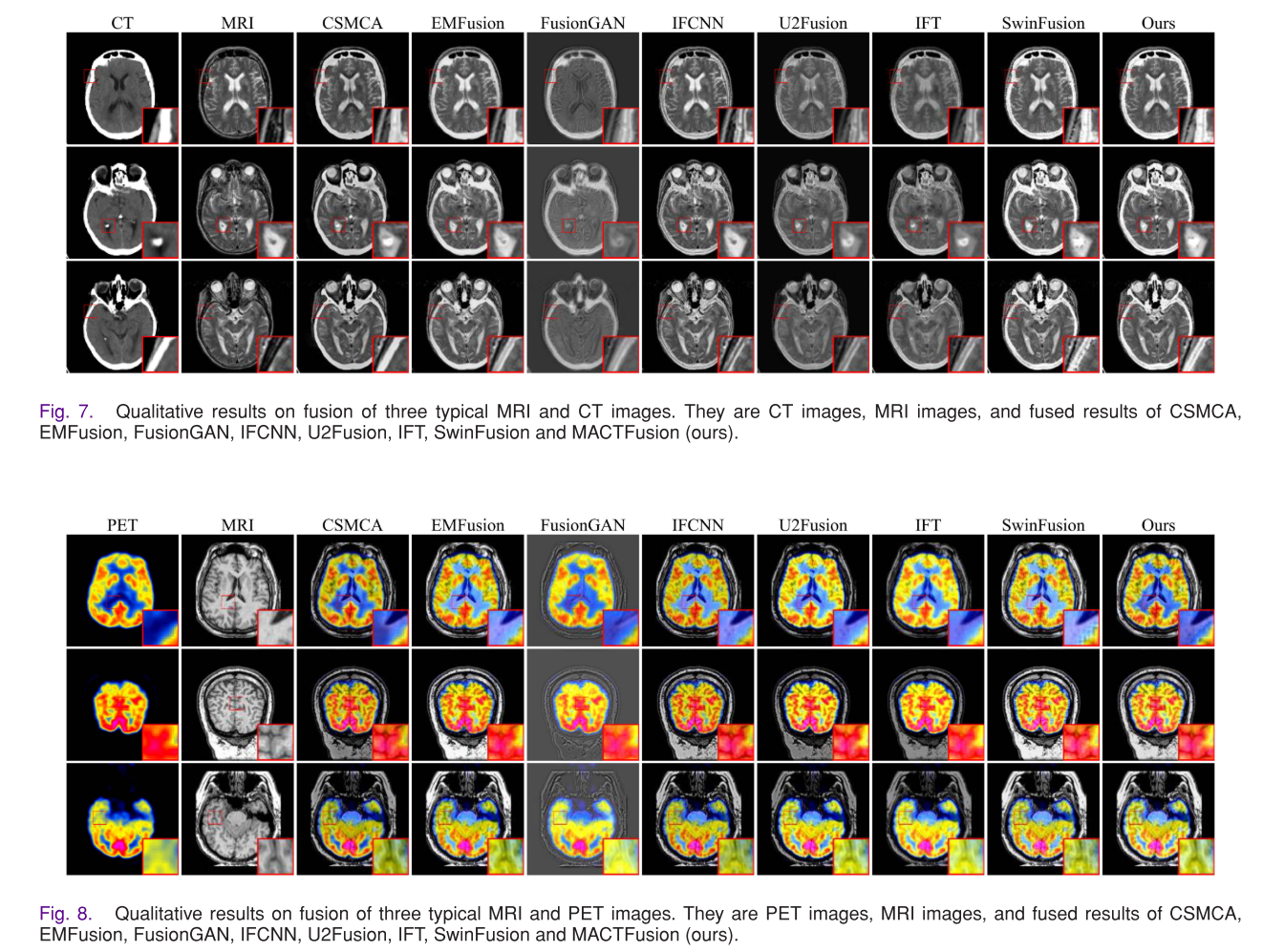
- CT - MRI融合:使用哈佛医学数据集,MACTFusion在保留CT的密集信息和MRI的纹理细节方面表现出色,在各项定量指标上取得最优结果。
- PET - MRI融合:该模型能较好地保留PET的功能信息和MRI的纹理细节,颜色分布更接近PET图像,在多个定量指标上表现优异。
- SPECT - MRI融合:MACTFusion获取了更多细节并保留了SPECT图像的适当颜色信息,在多数指标上取得最优结果。
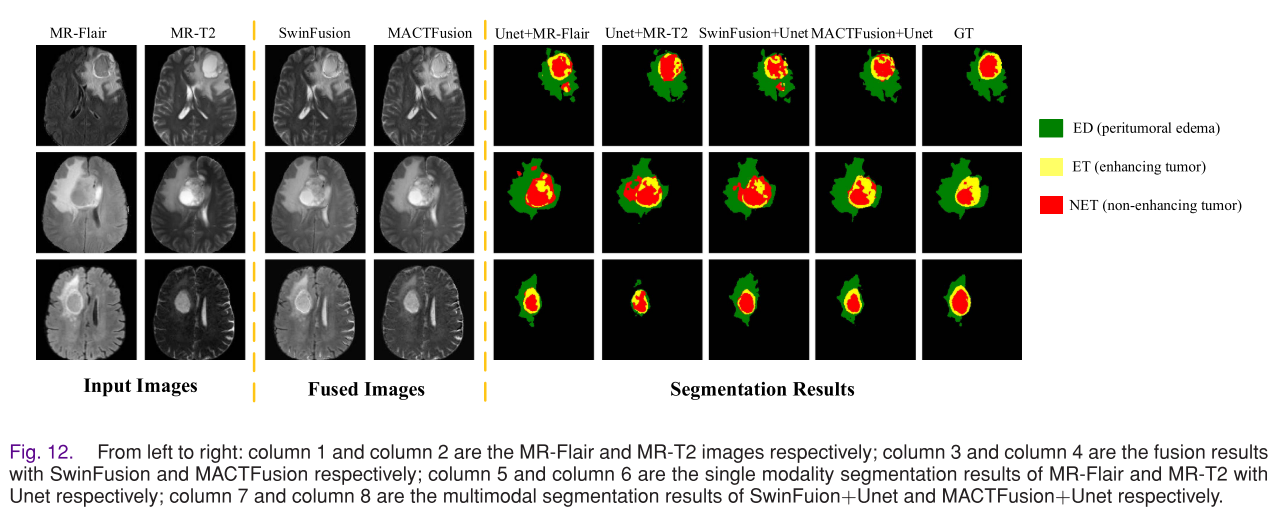
临床多模态脑肿瘤图像融合实验:与临床医生合作,对脑胶质瘤、转移性肿瘤和脑膜瘤的MR - T1和MR - T2图像进行融合。融合结果清晰度更高、纹理信息更丰富,有助于医生评估肿瘤异质性和了解肿瘤对周围脑组织的浸润情况。
GFP和PC图像融合实验:验证了MACTFusion的泛化能力,该模型与SwinFusion一样,能有效保留纹理和颜色信息。
医学图像分割应用实验:将融合结果应用于医学图像分割任务,MACTFusion的分割结果比单模态图像和SwinFusion的结果更准
实验(Ablation Experiments)
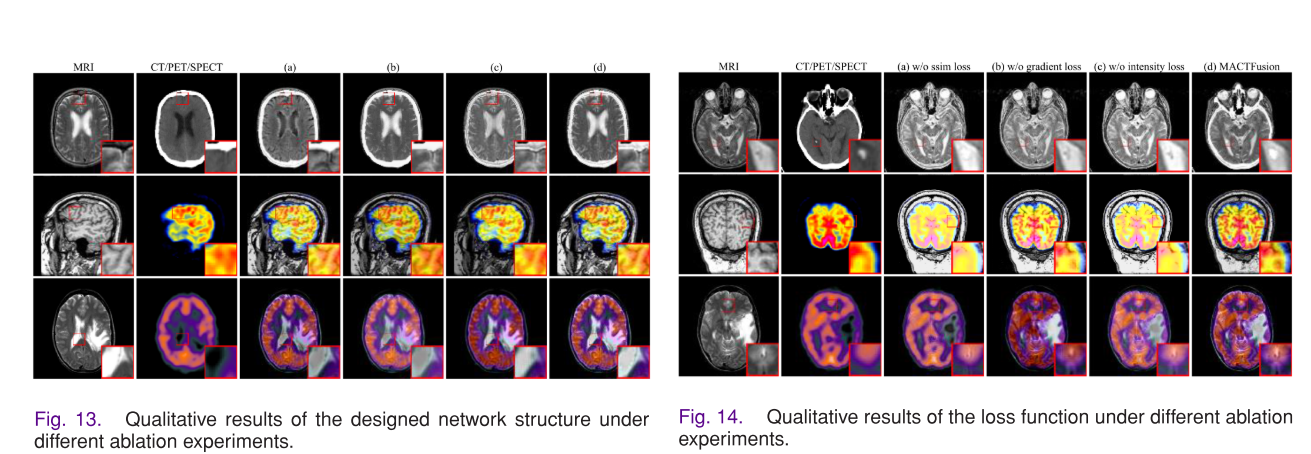
- 网络架构分析:对浅特征提取模块(SFE)、空间自适应融合模块(SAFM)和跨模态融合Transformer(CMFT)进行消融实验。结果表明,缺少这些模块会导致相应指标下降,影响模型提取细节、映射特征分布和整合补充信息的能力。
- 损失函数分析:对联合损失函数中的结构相似性损失Lssim、梯度损失Lgrad和强度损失Lint进行消融实验。结果显示,缺少任何一个子损失都会影响融合性能,而联合损失函数使MACTFusion在所有评估指标上取得最优结果。
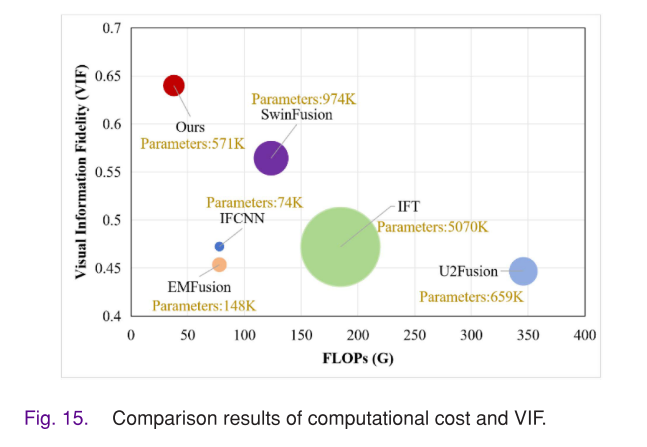
计算复杂度分析
通过训练参数数量和FLOPs评估实现效率,MACTFusion的FLOPs最小,训练参数数量少于IFT和SwinFusion,训练运行时间约为SwinFusion的四分之一,同时VIF表现最佳,证明该方法高效有效。
结论
在这项工作中,我们提出了一种新的轻量级自适应交叉Transformer架构,命名为MACTFusion,用于多模态医学图像融合。设计的交叉多轴注意机制包括交叉窗口注意以整合局部特征,以及交叉网格注意以整合来自不同模态的全局特征。具体来说,我们引入了空间自适应融合模块来引导交叉Transformer,使模型聚焦于最相关的信息。此外,我们设计了一个特殊的特征提取模块,该模块结合了多个梯度残差密集卷积和Transformer层,以从粗到细获取局部特征,并有效捕获全局特征。值得注意的是,所提出的模型在保持卓越融合性能的同时,尽量减少了计算成本。大量实验结果表明,我们的模型优于其他先进的融合技术。因此,它在后续诊断、治疗计划和手术导航中具有重要的应用价值。未来,我们将尝试将提出的MACTFusion应用于临床医学图像融合。此外,我们还将扩展其应用至3D图像融合。
- 方法优势:设计的交叉多轴注意力机制能整合不同模态的局部和全局特征,空间适应融合模块引导交叉 Transformer 聚焦关键信息,特殊特征提取模块可有效获取局部和全局特征。该模型在降低计算成本的同时,保持了出色的融合性能。
- 实验验证:大量实验结果表明,MACTFusion 优于其他先进融合技术,在后续诊断、治疗规划和手术导航等方面具有重要应用价值。
- 未来展望:未来将把 MACTFusion 应用于临床医疗图像融合,并拓展到 3D 图像融合领域。




