
摘要
Adapting a medical image segmentation model to a new domain is important for improving its cross-domain transferability, and due to the expensive annotation process, Unsupervised Domain Adaptation (UDA) is appeal-
ing where only unlabeled images are needed for the adaptation. Existing UDA methods are mainly based on image or feature alignment with adversarial training for regularization, and they are limited by insufficient supervision in the target domain. In this paper, we propose an enhanced Filtered Pseudo Label (FPL+)-based UDA method for 3D medical image segmentation. It first uses cross-domain data augmentation to translate labeled images in the source domain to a dual-domain training set consisting of a pseudo source-domain set andapseudo target-domain set. To leverage the dual-domain augmented images to train a pseudo label generator, domain-specific batch normalization layers are used to deal with the domain shift while learning the
domain-invariant structure features, generating high-quality pseudo labels for target-domain images. We then combine labeled source-domain images and target-domain images with pseudo labels to train a final segmentor, where image-level weighting based on uncertainty estimation and pixel-level weighting based on dual-domain consensus are proposed to mitigate the adverse effect of noisy pseudo labels. Experiments on three public multi-modal datasets for Vestibular Schwannoma, brain tumor and whole heart segmentation show that our method surpassed ten state-of-the-art UDA methods, and it even achieved better results than fully supervised learning in the target domain in some cases.
翻译
将医学图像分割模型适应到新的领域对于提高其跨领域的可迁移性至关重要,由于标注过程昂贵,无监督领域适应(UDA)显得极具吸引力,因为只需要未标注的图像进行适应。现有的UDA方法主要基于图像或特征对齐,通过对抗训练进行正则化,但在目标领域中由于监督不足而受到限制。本文提出了一种增强的基于过滤伪标签(FPL+)的UDA方法,用于3D医学图像分割。首先,使用跨领域数据增强将源领域的标注图像转换为由伪源领域集和伪目标领域集组成的双域训练集。为了利用双域增强图像训练伪标签生成器,使用特定领域的批归一化层来处理领域偏移,同时学习领域不变的结构特征,为目标领域图像生成高质量的伪标签。随后,我们结合带有伪标签的源领域标注图像和目标领域图像训练最终分割器,其中基于不确定性估计的图像级加权和基于双域一致性的像素级加权被提出以减轻噪声伪标签的不利影响。在三个公共多模态数据集上的实验,涉及前庭神经鞘瘤、脑肿瘤和全心分割,显示我们的方法超越了十种最先进的UDA方法,甚至在某些情况下在目标领域中取得了比完全监督学习更好的结果。
研究背景
这篇文章聚焦于3D医学图像跨模态分割模型的无监督域适应方法研究,其研究背景主要源于以下两方面问题:
- 跨模态性能差异大:医学图像存在多种模态,不同模态间有显著的域差距,如前庭神经鞘瘤分割中的增强T1(ceT1)和高分辨率T2(hrT2)磁共振成像。用一种模态训练的模型在其他模态图像上表现差,且为每种模态手动标注医学图像耗时费力,直接应用训练模型或分别训练新模型都不现实。
- 现有方法局限性:早期域适应方法需在源域和目标域进行标注,无监督域适应(UDA)虽有潜力,但现有UDA方法多基于图像或特征对齐与对抗训练正则化,主要针对2D医学图像分割,在3D医学图像分割上性能有限。此外,伪标签在UDA中的应用研究较少,因其受源域和目标域间显著域偏移影响,难以生成可靠伪标签,且直接使用含大量噪声的伪标签会误导目标域分割模型训练。
研究现状
- 深度学习在医学图像分割取得进展:如脑胶质瘤和前庭神经鞘瘤分割算法性能接近手动分割,但不同模态医学图像间存在显著领域差距,模型跨模态表现不佳。
- 领域适应方法涌现:早期领域适应方法需源域和一定程度的目标域标注,半监督DA利用少量标注和大量未标注图像进行适应。无监督领域适应(UDA)成为热门,现有方法主要基于图像或特征对齐,结合对抗训练进行正则化。
- 伪标签学习受关注:伪标签广泛用于训练标注不足或弱标注的分割模型,但在UDA中的应用研究较少。
提出的模型
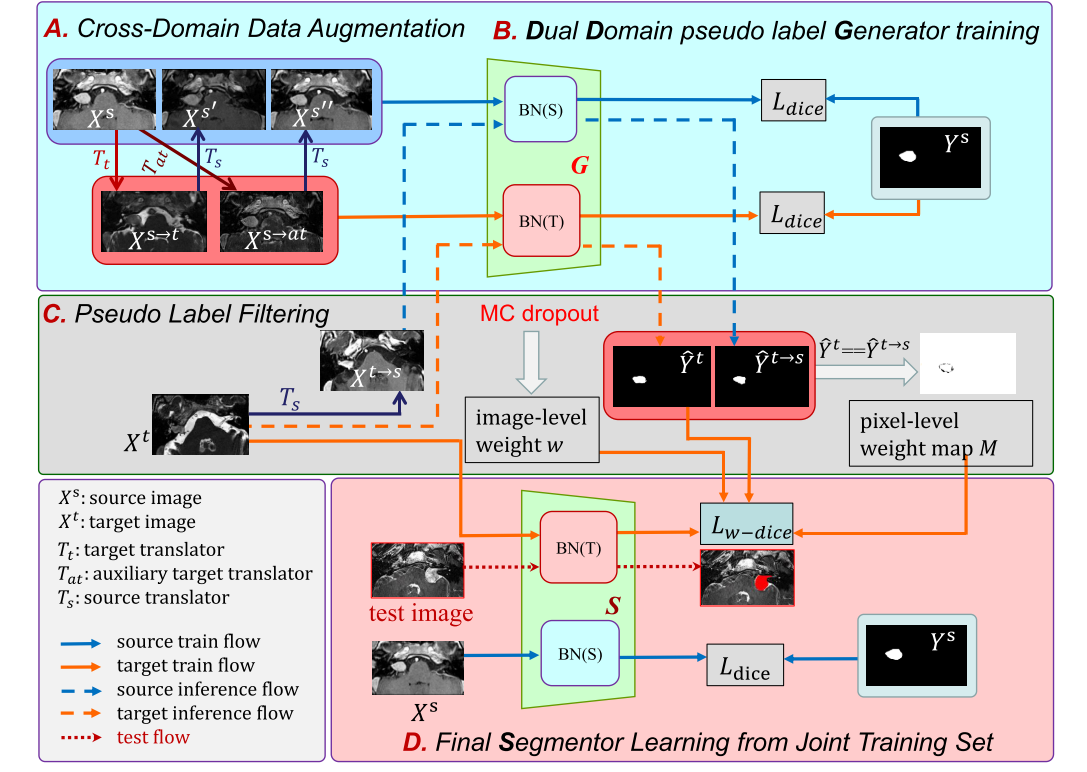
本文提出了一种基于增强过滤伪标签(FPL+)的**无监督域自适应(UDA)**方法用于3D医学图像分割,以下是该模型的主要构成和关键步骤:
1. 跨域数据增强(Cross - Domain Data Augmentation, CDDA)
- 目的:为了缓解源域和目标域之间的域差距,生成更多可用于训练的样本。
- 具体操作:利用图像风格转换器$T_t$和辅助目标风格转换器$T_{at}$将标记的源域图像$X_{s_i}$转换为两个伪目标域图像$X_{s\rightarrow t_i}$和$X_{s\rightarrow at_i}$,再将它们分别通过$T_s$转换回两个伪源域图像$X_{s’_i}$和$X_{s’’_i}$。这样每个标记的源域图像可以得到四个增强图像,且它们共享相同的分割标签$Y_{s_i}$。增强后的源域训练集$D_{ss} = {X_{s_i}, X_{s’_i}, X_{s’’_i}}$和伪目标域训练集$D_{st} = {X_{s\rightarrow t_i}, X_{s\rightarrow at_i}}$用于训练伪标签生成器。
- 训练损失:图像转换器$T_s$和$T_t$基于CycleGAN实现,训练涉及两个对抗损失$L_{t_{gan}}$、$L_{s_{gan}}$和一个循环一致性损失$L_{cyc}$。
2. 双域伪标签生成器(Dual - Domain pseudo label Generator, DDG)
- 目的:学习增强后的双域图像,为目标域训练集提供高质量的伪标签。
- 具体操作:使用双域批量归一化(Dual - BN)层处理域偏移,同时学习域不变的结构特征。在某一层中,从源域提取的特征由源域BN层归一化,从目标域提取的特征由目标域BN层归一化。
- 损失函数:使用Dice损失$L_{dice}$在$D_{ss}$和$D_{st}$上训练$DDG$。
3. 伪标签过滤(Pseudo Label Filtering)
- 目的:抑制不可靠的伪标签,提高最终分割器的训练效果。
- 基于尺寸感知不确定性估计的图像级加权:使用蒙特卡罗(MC)Dropout进行不确定性估计,计算每个目标域图像的方差图$V_j$,并根据估计的不确定区域大小$\eta_j$对图像级不确定性$v_j$进行归一化,得到图像级不确定性$u_j$,进而计算图像级权重$w_j$。
- 基于双域一致性的像素级加权:将目标域图像$X_{t_j}$通过$T_s$转换为伪源域图像$X_{t\rightarrow s_j}$,并使用$DDG$得到另一个伪标签$\hat{Y}_{t\rightarrow s_j}$。通过比较$\hat{Y}_{t\rightarrow s_j}$和$\hat{Y}_{t_j}$,将一致和不一致的区域分别视为可靠和不可靠的预测,定义像素级权重图$M_j$。最后将图像级权重$w_j$和像素级权重图$M_j$组合成单一权重图$A_j = M_j \cdot w_j$,并使用加权Dice损失$L_{w - dice}$进行训练。
4. 最终分割器学习(Final Segmentor Learning)
- 目的:结合源域标记图像和带有伪标签的目标域图像进行联合训练,学习域不变特征,提高在目标域的分割性能。
- 具体操作:最终分割器$S$采用与伪标签生成器$G$相同的架构,基于双域批量归一化层设计。其训练损失结合了源域的Dice损失和目标域的加权Dice损失。为了加速训练,最终分割器$S$使用伪标签生成器$G$的权重进行初始化。在测试阶段,直接使用训练好的最终分割器$S$进行推理。
实验(Compared with SOTA)
前庭神经鞘瘤分割数据集(Vestibular Schwannoma Segmentation Dataset):使用公开的包含242名患者的3D MRI图像数据集,有对比增强T1加权(ceT1)和高分辨率T2加权(hrT2)两种模态。将其随机分为200个训练样本、14个验证样本和28个测试样本,进行双向适应实验。实验前对图像进行裁剪和归一化预处理。
脑肿瘤分割数据集(BraTS Dataset):采用2020年多模态脑肿瘤分割挑战赛数据集,使用T2和FLAIR图像进行双向适应,目标是分割整个肿瘤。从官方训练集中选取样本,部分用于验证和测试。对图像进行强度归一化和去除无肿瘤切片的预处理。
心脏分割数据集(MMWHS Dataset):该数据集包含20个3D CT扫描和20个3D MRI扫描,分割目标包括升主动脉(AA)、左心房血腔(LAC)、左心室血腔(LVC)和左心室心肌(MYO)。指定MRI为源域,CT为目标域,划分训练、验证和测试集,并对图像进行裁剪和归一化。
实现细节:伪标签生成器G和最终分割器S基于改进的2.5D网络实现,添加额外的BN层用于双域批量归一化。使用Adam优化器训练,G训练200个周期,S初始化后训练100个周期。设置不同的补丁大小和批量大小,按照CycleGAN实现训练图像翻译器Ts和Tt。蒙特卡罗dropout的超参数K设为5,熵阈值e设为0.2。使用PyTorch 1.8.1在NVIDIA GeForce RTX 2080Ti GPU上实现实验,通过Dice分数和平均对称表面距离(ASSD)定量评估分割性能。
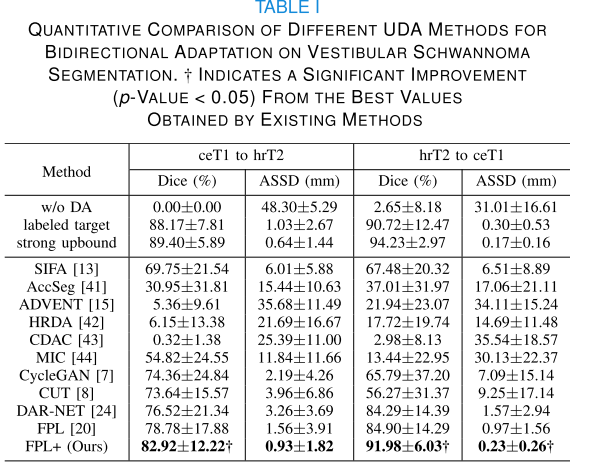
将FPL+与十种最先进的无监督域适应(UDA)方法进行比较,同时还与“w/o DA”(直接应用源域训练的模型到目标域)、“labeled target”(使用目标域全注释图像训练)和“strong upbound”(使用源域和目标域的标注图像训练双域分割网络)进行对比。
- 前庭神经鞘瘤分割结果:“w/o DA”方法在两个方向上的平均Dice分数极低,表明两种模态间存在显著的域差距。所有UDA方法均有改进,FPL+在两个方向上的平均Dice分数分别达到82.92%和91.98%,显著高于其他方法,甚至在某些情况下优于“labeled target”。
- 脑胶质瘤分割结果:在“FLAIR到T2”和“T2到FLAIR”两个方向上,FPL+的平均Dice分数和ASSD均优于其他现有UDA方法,在“T2到FLAIR”方向上超过“labeled target”,略低于“strong upper bound”。
- 心脏分割结果:“w/o DA”的Dice分数远低于“labeled target”,表明MR和CT模态间存在明显的域差距。FPL+的平均Dice分数和ASSD分别为73.70%和2.61mm,显著优于现有UDA方法,能更准确地分割心脏子结构。
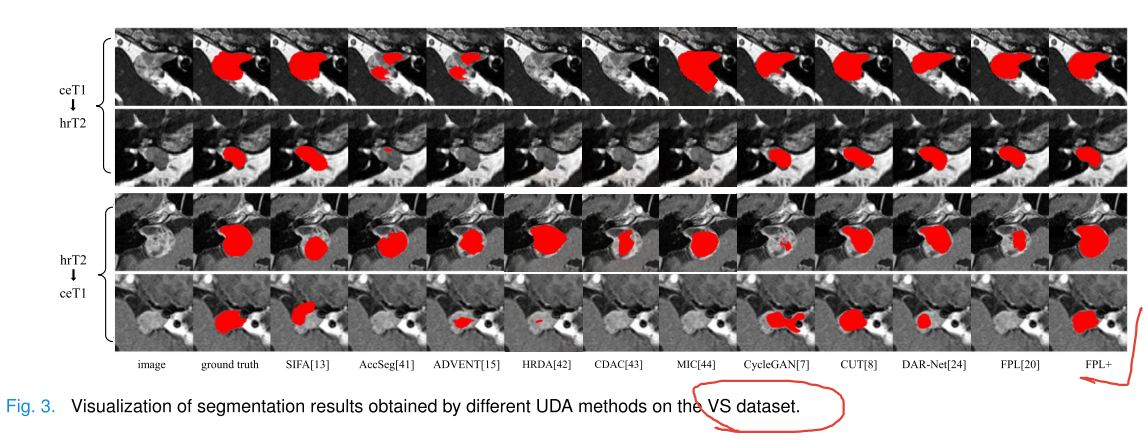
实验(Ablation Experiments)
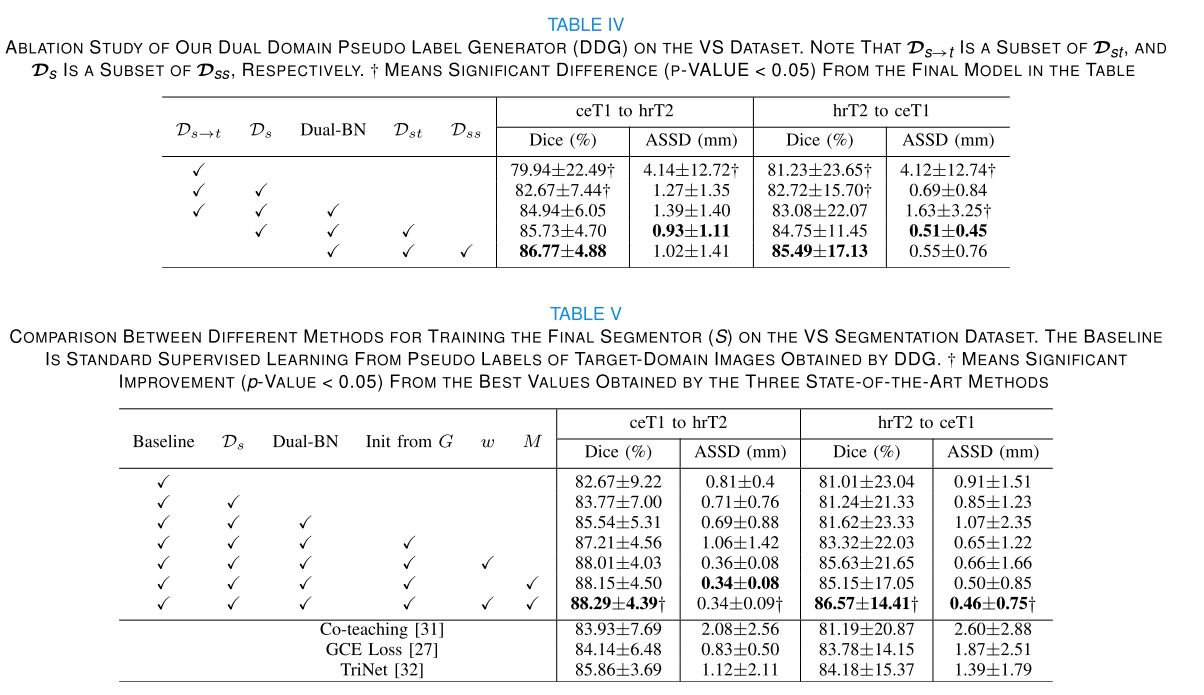
在VS数据集上对双域伪标签生成器(DDG)和最终分割器S进行全面的消融实验,验证FPL+各组件的有效性,并将伪标签过滤方法与几种现有的抗噪声学习方法进行比较。
- CDDA和Dual - BN对DDG的有效性:以仅使用Ds→t训练伪标签生成器为基线,实验表明结合Ds→t和Ds训练且不使用Dual - BN时性能有所提升,引入Dual - BN进一步提高性能,使用CDDA生成的双域增强图像结合Dual - BN能获得最高的平均Dice分数。
- 最终分割器训练的消融实验:以标准监督学习使用DDG生成的目标域伪标签为基线,逐步引入添加源域标注图像、使用Dual - BN、从G初始化S、图像级加权和像素级加权等组件。结果显示每个组件都能有效提高分割性能,结合图像级和像素级加权训练最终分割器能获得最佳效果。
- 与其他伪标签学习方法的比较:将FPL+训练S的策略与Co - teaching、GCE Loss和TriNet三种最先进的从噪声标签学习的方法进行比较,结果表明FPL+的性能优于这些方法。
- 超参数的有效性:研究了图像级加权的熵图阈值e和辅助翻译器训练周期数对性能的影响。结果显示e设置为0.2时性能最佳,辅助翻译器训练到200个周期时,伪标签生成器的性能达到峰值。

结论
作者提出了基于增强过滤伪标签(FPL+)的无监督跨模态适应方法用于3D医学图像分割,并得出以下结论:
- 方法有效性:通过跨域数据增强和图像、像素级加权等策略,有效对齐源域和目标域图像,筛选可靠伪标签,提升了模型跨域转移能力。在三个公共多模态数据集上的实验表明,该方法超越了十种最先进的无监督域适应(UDA)方法,在某些情况下甚至优于目标域的全监督学习。
- 方法局限性:方法涉及训练伪标签生成器和最终分割器两个步骤,增加了一定复杂性;因GPU内存和图像翻译伪影问题,难以实现3D图像的端到端生成和分割;要求源域和目标域的分割目标可见且拓扑相似。未来,该方法有望应用于其他分割任务。




