
云南大学、东南大学、紫金山实验室、阿利亚大学
摘要
The successful fusion of 3-D multi-modal medical images depends on both specific characteristics unique to each imaging mode as well as consistent spatial semantic features among all modes. However, the inherent variability in the appearance of these images poses a significant challenge to reliable learning of semantic information. To address this issue, this paper proposes a nested self-supervised learning framework for 3-D semantic segmentation-driven multi-modal medical image fusion. The proposed approach utilizes contrastive learning to effectively extract specified multi-scale features from each mode using U-Net (CU-Net). Subsequently, it employs geometric spatial consistency learning through a fusion convolutional decoder (FCD) and a geometric matching network (GMN) to ensure consistent acquisition of semantic representation within the same 3-D regions across multiple modalities. Additionally, a hybrid multi-level loss is introduced to facilitate the learning process of fused images. Ultimately, we leverage optimally specified multi-modal features for fusion and brain tumor lesion segmentation. The proposed approach enables cooperative learning between 3-D fusion and segmentation tasks by employing an innovative nested self-supervised strategy, thereby successfully striking a harmonious balance between semantic consistency and visual specificity during the extraction of multi-modal features. The fusion results demonstrated a mean classification SSIM, PSNR, NMI,and SFR of 0.9310, 27.8861, 1.5403, and 1.0896 respectively. The segmentation results revealed a mean classification Dice, sensitivity (Sen), specificity (Spe), and accuracy (Acc) of 0.8643, 0.8736, 0.9915, and 0.9911 correspondingly. The experimental findings demonstrate that our approach outperforms 11 other state-of-the-art fusion methods and 5 classical U-Net-based segmentation methods in terms of 4 objective metrics and qualitative evaluation. The code of the proposed method is available at https://github.com/ImZhangyYing/NLSF.
翻译
3D多模态医学图像的成功融合依赖于每种成像模式独特的具体特征以及所有模式之间一致的空间语义特征。然而,这些图像外观的固有变化对语义信息的可靠学习构成了重大挑战。为了解决这一问题,本文提出了一种用于3D语义分割驱动的多模态医学图像融合的嵌套自监督学习框架。所提出的方法利用对比学习通过U-Net (CU-Net)有效地从每种模式中提取指定的多尺度特征。随后,它通过融合卷积解码器(FCD)和几何匹配网络(GMN)进行几何空间一致性学习,以确保在多个模态的相同3D区域内一致地获取语义表示。此外,引入了一种混合多层次损失来促进融合图像的学习过程。最终,我们利用最佳指定的多模态特征进行融合和脑肿瘤病灶分割。所提出的方法通过使用创新的嵌套自监督策略,实现了3D融合和分割任务之间的协同学习,从而在多模态特征提取过程中成功地在语义一致性和视觉特异性之间达到了和谐的平衡。融合结果显示,平均分类SSIM、PSNR、NMI和SFR分别为0.9310、27.8861、1.5403和1.0896。分割结果揭示了平均分类Dice、灵敏度(Sen)、特异性(Spe)和准确性(Acc)分别为0.8643、0.8736、0.9915和0.9911。实验结果表明,我们的方法在4个客观指标和定性评估方面优于其他11种先进的融合方法和5种经典U-Net分割方法。所提出方法的代码可在https://github.com/ImZhangyYing/NLSF
研究背景
本文的研究背景主要围绕多**模态医学图像融合(MMIF)和分割(MMIS)**展开,现有方法存在诸多不足,具体如下:
- 医学影像需求:在医学成像领域,不同模态影像能提供互补信息,综合各模态信息对准确诊断至关重要。3D医学影像相比2D影像,能提供更丰富的空间信息,在手术规划和复杂病例诊断中更具优势。
- 现有MMIF方法局限:大部分现有方法针对2D多模态医学图像,难以保留人体解剖结构的3D空间信息;多聚焦于多模态的视觉特异性,忽视了多模态图像间的空间语义一致性;缺乏对融合和下游任务的统一建模,现有分割方法未将MMIF任务作为有效先验来提升MMIS任务性能。
- 对比学习与语义一致性问题:现有自监督学习在对比学习中虽能区分各模态特征,但忽视了3D医学图像中空间语义特征的一致性,无法准确捕捉图像间的语义信息。 为解决上述问题,本文提出了一种用于3D语义分割驱动的多模态医学图像融合的嵌套自监督学习框架(NSLF)。
研究现状
- 融合方法:分为传统方法(如基于稀疏表示、多尺度变换)和深度学习方法(如基于CNN、AE)。现有方法在多模态医学图像融合(MMIF)和多模态医学图像分割(MMIS)中取得一定成果,但多针对2D图像,且难以有效捕捉全局依赖。
- 对比学习与语义一致性:现有自监督学习在对比学习方面有进展,能区分各模态独特特征,但忽略了3D医学图像的空间语义相似性,难以捕捉图像间语义信息。
提出的模型
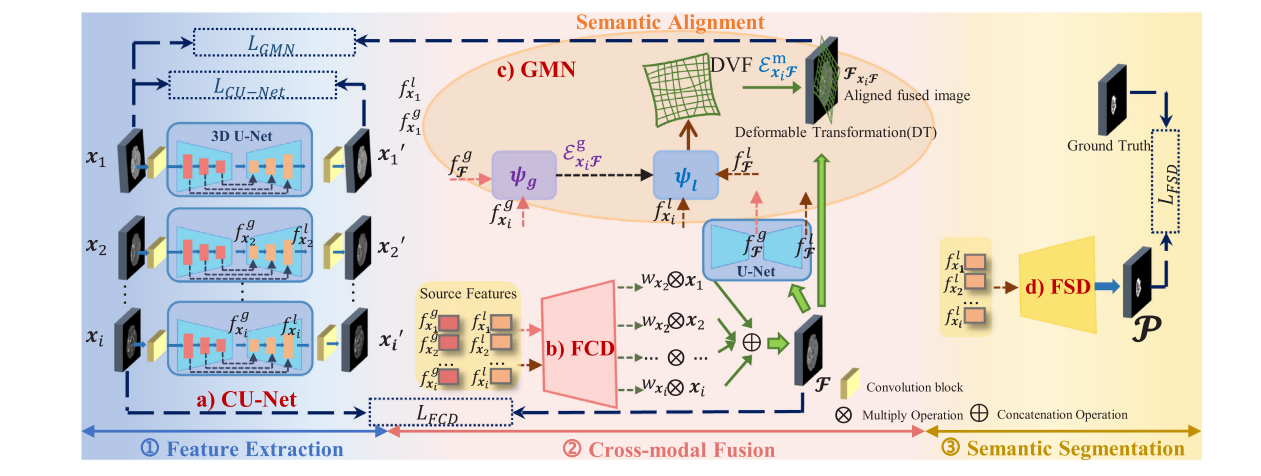
NSLF框架由四个关键组件构成,分别为对比U型网络(Contrastive U-Net,CU-Net)、融合卷积解码器(Fusion Convolutional Decoder,FCD)、几何匹配网络(Geometric Matching Network,GMN)和特征分割解码器(Feature Segmentation Decoder,FSD)。
- CU-Net:作为特征提取器,通过对比学习从单模态图像中捕获全局和局部特征。它由一组3D U-Net组成,每个U-Net包含多个Maxpool3d层、Conv3d层、BN3d层、激活函数和ConvTranspose3d层。通过对比损失函数约束U-Net参与对比学习,以获取各模态的特定特征。
- FCD:融合卷积解码器,以CU-Net提取的局部和全局特征为输入,生成源图像的融合概率,进而得到融合结果。它由四个ConvTranspose3d和Conv3d层,以及一个额外的Conv3d层组成。
- GMN:设计用于确保多模态图像在相同3D语义区域的空间语义一致性。通过结合仿射变换(Affine Transformation,AT)和可变形变换(Deformable Transformation,DT),在多尺度上对融合结果和源图像进行语义对齐。其中,仿射变换用于全局图像对齐,可变形变换用于局部图像对齐。
- FSD:特征分割解码器,以CU-Net提取的源图像局部特征为输入,进行语义分割并得到分割结果。它包含拼接操作、四个Conv3d层、BN3d层、激活函数和一个Conv3d层。
训练策略
采用多阶段嵌套结构对嵌套自监督学习框架进行训练,具体分为三个阶段:
- 特征提取阶段:预训练CU-Net,通过对比损失函数约束其对源图像进行重建,以提取特定的多尺度特征。
- 多模态融合阶段:训练FCD生成融合结果,同时训练GMN以确保语义表示的一致性,并微调预训练CU-Net的参数。
- 语义分割阶段:训练FSD,并进一步微调预训练CU-Net的参数。
损失函数
为每个训练阶段设计了相应的损失函数,以指导模型的训练过程:
- 特征提取阶段损失:该阶段的损失主要是CU-Net的对比损失,旨在最小化正样本对之间的距离,同时最大化负样本对之间的距离。
- 多模态融合阶段损失:此阶段的损失由两部分组成,FCD的融合损失和GMN的几何一致性损失。融合损失包括保真损失、亮度损失和结构相似性损失,用于约束融合图像与源图像在像素级的视觉相似性;几何一致性损失用于衡量源图像和融合图像在拓扑结构上的相似性,并计算体素位移矢量场(DVF)的平滑损失,以确保模型学习到一致的语义表示。
- 语义分割阶段损失:该阶段的损失为FSD的分割损失,由Dice损失和交叉熵损失组成,用于评估预测掩码与真实标签之间的差异。
实验(Compared with SOTA)
- 数据集:使用了BraTS 2021挑战赛的开源多模态MRI数据集,包括训练集、验证集和测试集。
- 对比实验:在3D/2D多模态医学图像融合和分割任务中,将NSLF与11种最先进的融合方法和5种经典的基于U-Net的分割方法进行了对比。
- 评估指标:采用结构相似性指数(SSIM)、峰值信噪比(PSNR)、归一化互信息(NMI)、空间频率响应(SFR)、Dice系数、灵敏度(Sen)、特异性(Spe)和准确率(Acc)等指标对模型性能进行评估。
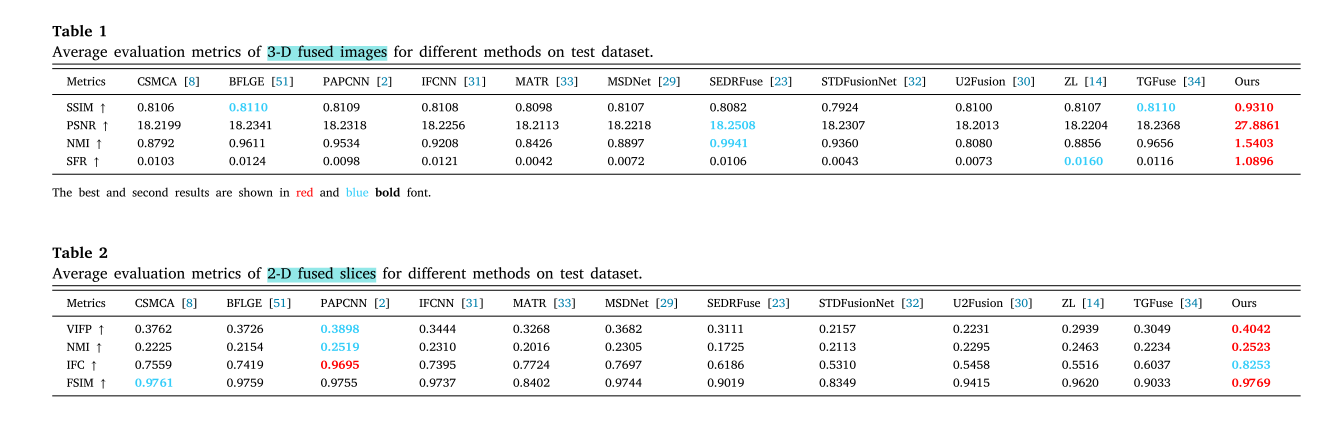
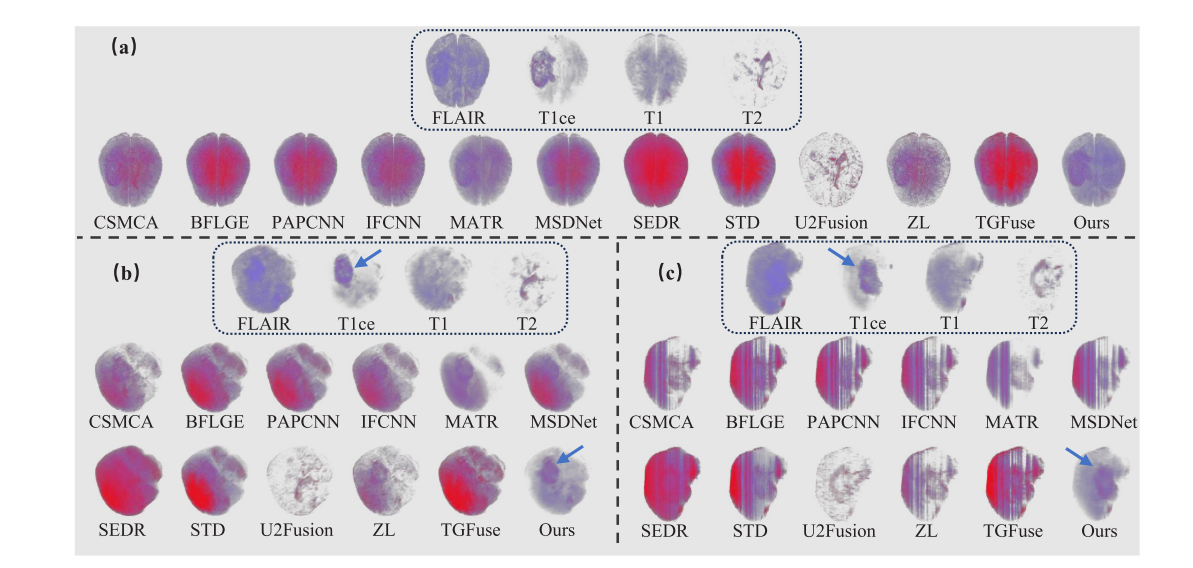
- 二维/三维多模态医学图像融合(2-D/3-D MMIF)
- 训练细节:使用PyTorch在4090 GPU上训练模型,对CU - Net和FCD应用Adam优化器,采用余弦退火策略调整学习率,权重衰减设为5e - 4,初始学习率1e - 4,最小学习率1e - 5。设置早停机制,耐心值为10。批大小为1,最大训练轮数为30。将所有输入图像中心裁剪为808064后输入网络。
- 对比方法:与11种先进的融合方法进行比较,包括3种传统方法(CSMCA、BFLGE、NSST - PAPCNN)和8种深度学习方法(IFCNN、MATR、MSDNet、SEDRFuse、STDFusionNet、U2Fusion、ZL、TGFuse)。
- 评估指标:三维融合使用结构相似性指数(SSIM)、归一化互信息(NMI)、峰值信噪比(PSNR)和空间频率响应(SFR)四个客观指标;二维融合使用特征相似性指数(FSIM)、基于像素的视觉信息保真度(VIFP)、归一化互信息(NMI)和信息保真度准则(IFC)。
- 定性评估:三维采用直接体渲染(DVR)对图像进行可视化分析,结果表明所提方法能有效呈现肿瘤病变的空间信息;二维将三维融合结果切片后选取120对进行测试,结果显示其他一些方法在保留病变信息和细节方面存在不足。
- 定量评估:从测试集中选取10个多对比度MRI展示三维融合平均结果,所提方法在所有三维指标上排名第一;将三维融合结果切片为二维后选取120对测试,除PAPCNN的IFC指标外,所提方法在其他指标上表现最佳。
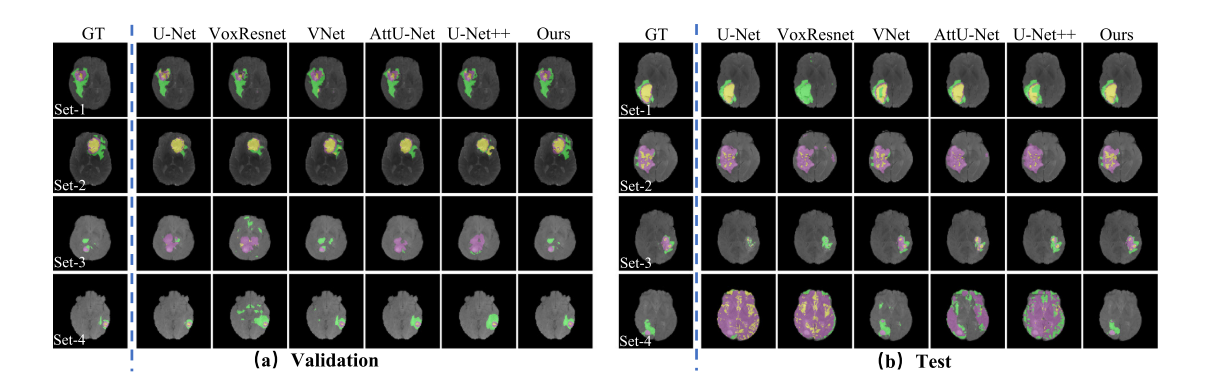
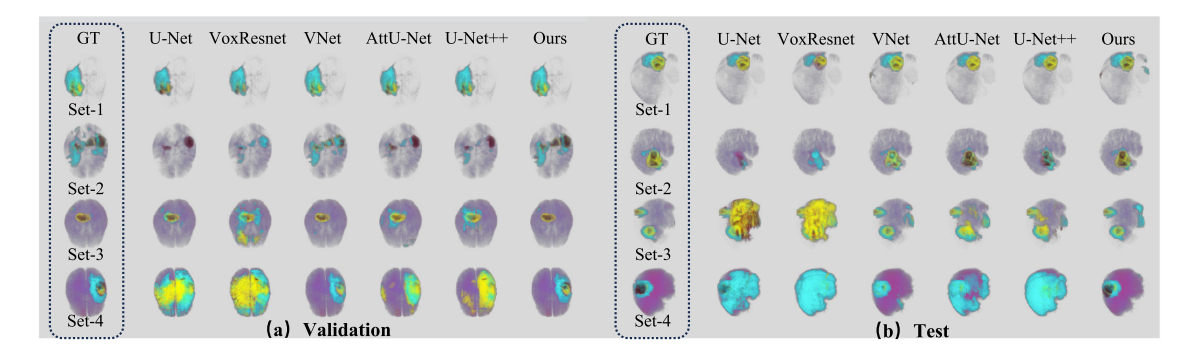
- 二维/三维多模态医学图像分割(2-D/3-D MMIS)
- 训练细节:同样使用PyTorch在4090 GPU上训练,训练设置与图像融合类似。输入图像中心裁剪为16016064后输入网络,在验证和测试阶段,根据增强肿瘤(ET)、肿瘤核心(TC)和整个肿瘤(WT)三个肿瘤区域的表现进行评估。
- 对比方法:与5种基于U - Net的先进方法(U - Net、VoxResNet、V - Net、Attention U - Net、U - Net++)进行比较,实验在相同条件下进行以确保公平性。
- 评估指标:使用骰子系数(Dice)、敏感性(Sen)、特异性(Spe)和准确性(Acc)四个指标评估脑肿瘤病变的三维分割性能。
- 定性评估:展示了不同复杂程度的多对比度MRI的分割可视化结果,结果表明U - Net基方法在简单数据上表现较好,但随着数据复杂度增加会出现明显分割错误,而所提方法在不同复杂度图像上都能取得最佳性能。
- 定量评估:在BraTS 2021验证集和测试集上验证,结果显示所提框架在Dice、Sen和Acc指标上优于其他模型,在TC的Spe指标上排名第二。
实验(Ablation Experiments)
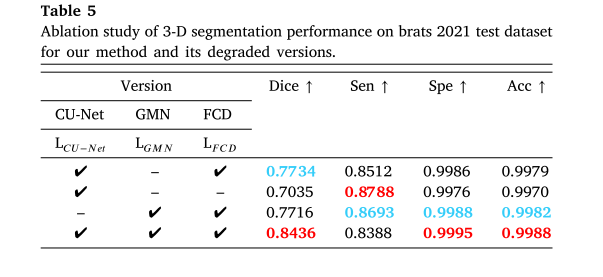
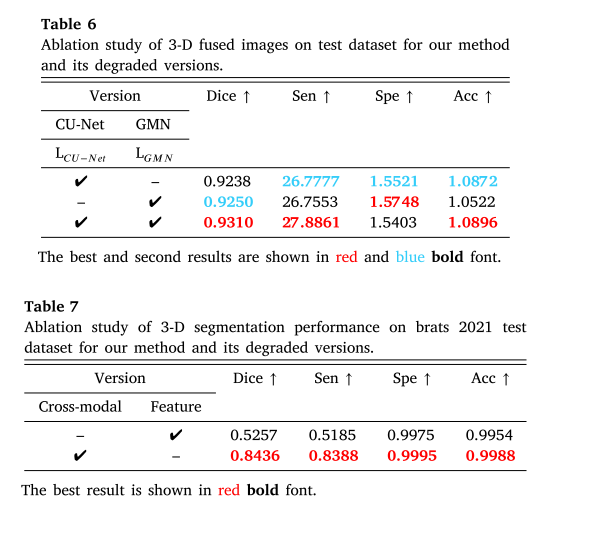
- 三维语义分割:将NSLF退化得到不同版本,实验表明GMN和CU - Net对框架有显著贡献,缺少它们的版本在融合和分割任务中性能变差。
- 三维融合:对比不同版本在三维融合上的表现,结果显示所提方法整体性能最佳,缺少CU - Net和GMN的版本在部分指标上表现较差。
- 语义分割驱动的融合:创建仅使用融合结果训练分割网络的退化版本,实验表明所提方法在综合性能上更优,嵌套自监督学习能提高分割质量。
结论
本文提出了一种用于**多模态医学图像融合(MMIF)和多模态医学图像分割(MMIS)**任务的嵌套自监督学习框架(NSLF),主要结论如下:
- 方法概述:NSLF由特征提取器(CU - Net)、融合解码器(FCD)、几何匹配网络(GMN)和分割解码器(FSD)组成。通过对比学习从CU - Net获取源图像的特定多尺度特征,并将其输入到FCD、GMN和FSD中,以支持融合和分割任务。GMN对特征提取和融合网络施加几何一致性约束,确保框架提取的多模态特征具有一致的语义信息。
- 实验结果:综合实验结果验证了该方法在视觉效果和定量分析方面的优越性。在3 - D多模态脑MRI融合任务中,该方法在SSIM、PSNR、NMI和SFR等指标上优于11种先进的融合方法;在多模态脑MRI的多病灶3 - D分割任务中,该方法在Dice、Sen、Spe和Acc等指标上优于5种基于U - Net的经典分割方法。
- 方法局限性:本方法聚焦于保留多个源图像中的正确语义信息,但也存在一定局限性:
- 与其他融合模型相比,训练过程的计算复杂度较高。
- 由于难以同时保持多模态视觉特征和准确的语义信息,对局部细节信息的保留不够重视。
- 未来研究方向:未来研究将进一步探索在融合任务中保留语义信息和特定视觉特征之间的微妙平衡。此外,还将考虑替代学习技术,以研究和开发具有高泛化能力、低计算复杂度的通用框架,这些技术可能提供更快的处理速度、更高的可解释性,并且在参数数量、调优要求和资源需求较少的情况下达到可比的性能。




